
In 2025, artificial intelligence has fundamentally transformed how creators produce, share, and localize video content. Among the most powerful innovations driving this creative revolution is Lip Sync AI technology — a breakthrough that allows users to make any face talk, sing, or speak naturally in any language without complex re-recording or dubbing.
The global lip-sync technology market is booming. It’s projected to reach USD 5.76 billion by 2034, growing at a CAGR of 17.8%, up from just USD 1.12 billion in 2024. This explosive growth reflects a shift from rule-based animation systems to advanced AI models powered by deep learning, generative adversarial networks (GANs), and diffusion models.
Whether you’re a content creator, marketer, educator, or filmmaker, understanding how Lip Sync AI works — and how to use it effectively — is now essential to staying competitive in the global digital landscape.

Understanding Lip Sync AI: Core Technology & How It Works
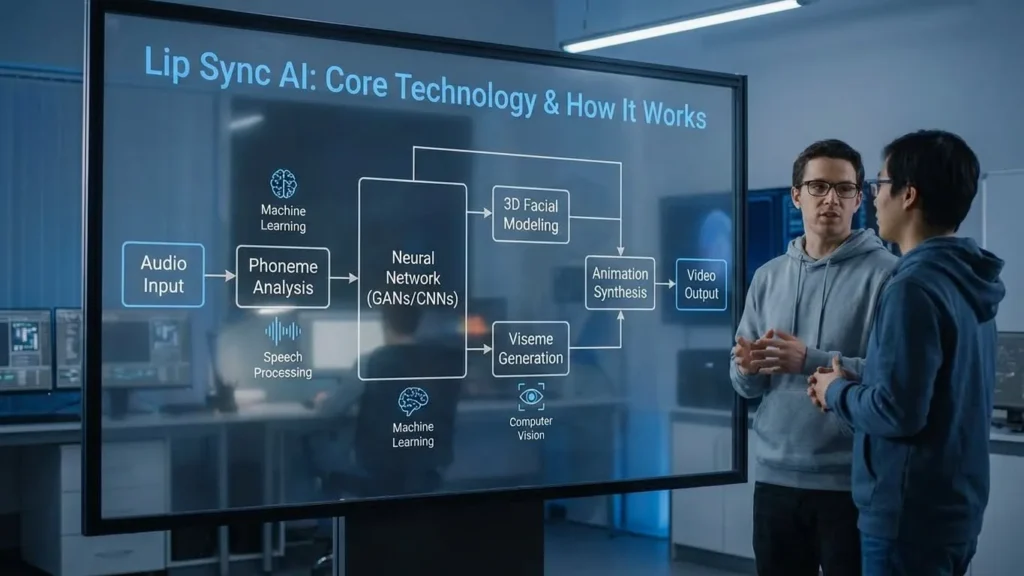
Lip Sync AI (also called lip synchronization AI) uses machine learning to match mouth movements in a video with a new audio track — whether it’s speech, music, or narration. Traditionally, animators had to draw or adjust each viseme (mouth shape for each sound), a time-intensive process that required expert skills. Today, AI automates this entire workflow.
The system works in several sophisticated steps. First, facial detection identifies key facial landmarks — mouth, eyes, jawline, and cheeks. Then, audio analysis interprets rhythm, phonemes, and tone from the input sound. Based on this, deep neural networks trained on massive video datasets predict natural mouth movements aligned with spoken audio.
Next comes lip movement generation, where AI animates lips frame-by-frame with impeccable timing and emotional realism. Finally, the rendering phase merges layers into a lifelike video where lip motion perfectly syncs with speech.
Over the years, Lip Sync AI’s architecture has evolved rapidly. Early systems relied on GANs like the famous Wav2Lip (2020), where a generator created lip movements and a discriminator ensured quality. Though revolutionary, GAN outputs often looked blurry or inconsistent between frames.
Cutting-edge diffusion models now outperform GANs by adding and removing noise through multiple stages to achieve higher fidelity, smoother transitions, and notably better realism. Additionally, transformer architectures enhance temporal understanding, ensuring characters speak fluidly across frames — not robotically frame-by-frame.
Lip Sync accuracy is measured using several technical benchmarks.
- LSE-D (Lip-Sync Error-Distance) tracks how closely audio and visual cues align. Wav2Lip-HQ achieves an outstanding LSE-D of 4.25, versus 6+ for older systems.
- LSE-C (Lip-Sync Confidence) indicates synchronization strength — Wav2Lip-HQ scores 6.39, reflecting near-perfect accuracy.
- SSIM (Structural Similarity) and PSNR (Peak Signal-to-Noise Ratio) measure visual realism, reaching 0.88 and 32.64, respectively.
- A FID score (23.18) confirms visual authenticity, while a TSS (0.85) shows excellent motion consistency across frames.
Emerging models push boundaries even further. StableSyncNet raised test accuracy on the HDTF dataset from 91% to 94%, reducing instability during training. Meanwhile, FlashLips achieves real-time 100-FPS performance with mask-free architectures, making it ideal for live streaming and gaming.
Popular AI Lip Sync Tools & Platforms in 2025
The number of practical AI lip-sync tools has exploded, catering to everyone from individual creators to enterprise studios.
- Vozo AI delivers ultra-realistic voice and lip alignment in minutes, even for multiple speakers or moving faces. It supports all major global languages and adjusts automatically for scene lighting and motion.
- Kapwing AI Lip Sync works flawlessly in more than 40 languages — including Hindi, Arabic, Spanish, and French — and lets users build digital avatars or brand personas for consistent video content.
- Sync.so, from the original Wav2Lip team, integrates real-time translation and diffusion-based lip-sync, achieving near-photorealistic speaking avatars.
- HeyGen supports 175+ languages and dialects, combining voice cloning, lip-sync, and subtitles for perfect multilingual localization.
- Hedra brings static images to life by analyzing audio patterns and predicting micro facial movements like blinks and eyebrow shifts — making profile photos or story characters speak naturally.
- Rask AI offers full-scale localization support for 135+ languages with robust voice cloning in 29 languages and multi-speaker synchronization — an all-in-one tool for global media teams.
Each platform targets different needs, from social videos to cinematic dubbing. Together, they mark a new era where anyone can create truly global, visually synchronized, and emotionally realistic content.
Pricing strategies vary significantly. Free tier options are available on platforms like HeyGen (3 videos per month up to 3 minutes), Synthesia (3 minutes per month), and Kling AI (66 free daily credits). Entry-level pricing ranges from $5-$30 per month, with Sync.so offering usage-based pricing at $0.95 per minute, Vozo AI at $29/month for 15 minutes of lip sync, and HeyGen’s Creator Plan at $29/month. Enterprise solutions with unlimited features, custom integrations, and compliance requirements (GDPR, SOC 2) cost $300+/month. A critical cost comparison: traditional manual dubbing costs upwards of $1,200 per minute of video, while AI alternatives cut localization costs by 70-90%. This represents a return on investment (ROI) almost immediately for content creators at scale.
For individual users evaluating tools in 2025, the decision matrix involves trade-offs. Dzine AI produces some of the most realistic lip sync animations available, with multiple character support, but costs approximately $16-$20 per month with premium features. LipDub AI excels with Hollywood-grade quality, handling extreme poses and close-ups while maintaining emotional nuance, ideal for professional productions unwilling to compromise on quality. CapCut’s AI Dialogue Scene offers convenience for users already in the CapCut ecosystem, with straightforward integration but at the cost of limited customization. Kling AI provides the most generous free tier (60 seconds daily), making it ideal for casual creators testing the technology before committing budget.
Practical Applications: From Entertainment to Education
The real-world applications of lip sync AI have expanded far beyond simple entertainment use cases. In content localization, creators can now produce the same video in multiple languages while keeping lip movements natural — making messages resonate with audiences worldwide. Educational content creators have leveraged this to convert one-language lessons into multilingual videos, reaching new learners without re-recording. A case study of an educational YouTuber demonstrated this clearly: by translating their content into 5 new languages using lip sync AI, they experienced a 45% increase in overall viewership, with particularly strong growth in non-English speaking markets. Viewer retention improved measurably because the lip syncing aligned with the language, creating a more natural and personalized viewing experience.
Social media content creation remains one of the highest-impact use cases. Creators on TikTok and YouTube Shorts use lip sync AI to turn selfies or static images into expressive videos, recreate trending music, and translate content to reach global audiences. A gaming YouTuber featured in case study research produced a character-driven series using AI lip sync to animate a 2D game character’s face — reducing workload from hours of manual animation to seconds of automated syncing. The result: a single episode reached 1.2 million views, with community engagement flooding the comments asking for more character episodes.
Entertainment and film production has adopted lip sync AI as a standard localization tool. Instead of hiring multiple voice actors or creating separate recordings for each language, studios can now automatically translate scripts, synchronize translated audio perfectly with the speaker’s lips, and maintain original tone and emotion for natural, localized experiences. This democratizes international distribution, enabling smaller studios to compete with major production houses on content quality while reducing budgets significantly.
Marketing and advertising uses talking photos or lip-synced spokesperson videos to deliver product messages in a more human and relatable way — without requiring on-camera talent. Brands create personalized video messages from brands or “digital influencers,” feeling more authentic and speaking directly to different audience segments in their native languages. This level of personalization creates deeper bonds with viewers and allows companies to deliver seemingly personal messages in many languages at lower costs than traditional localization.
Virtual reality (VR) and augmented reality (AR) applications have embraced lip sync AI to bring digital characters to life. Imagine attending a concert in VR where the singer’s lips move perfectly in sync with every word, or having an AR fitness coach whose immediate feedback is perfectly synchronized with their words of encouragement. With integrated AI lip-syncing, VR and AR become more realistic and interactive, making characters feel like real people whether in training simulations, social VR, or digital events.
Virtual humans and digital influencers represent an emerging frontier. AI-powered personas can now connect with audiences in various languages with natural lip movements and expressions, even responding in real-time to comments or questions. Brands are using these digital personalities to interact with consumers in new, progressive ways that feel more interactive and authentic.
Market Size, Growth Drivers, and Key Industry Players
North America currently dominates the global lip-sync technology market, capturing more than 37.3% of total share with an estimated USD 0.42 billion in 2024 revenue. Within this region, the U.S. market alone was valued at USD 0.39 billion in 2024 and is projected to grow to nearly USD 1.65 billion by 2034, reflecting an impressive 15.5% CAGR over the decade.
In terms of composition, software solutions lead the market with a 61.5% share, showcasing the growing dependence on AI-powered algorithms and real-time rendering tools. The audio-driven machine learning (AI-based technology) segment also holds a strong lead of 40.7%, powered by modern deep learning models that deliver higher synchronization accuracy and more natural lip movements.
Meanwhile, cloud-based deployment commands 56.3% of the market, underscoring demand for scalable, collaborative, and on-demand processing in content creation and localization workflows.
Key market drivers include rising demand for high-quality, multilingual streaming content, increased AI media production investment to reduce costs and improve dubbing efficiency, the need for localized content to reach regional markets, rising demand for realistic character lipsyncs in gaming and metaverse environments, and technological progress enabling live streaming and broadcast lip sync. Emerging trends include real-time lip sync for live video and broadcast synchronization, VR/AR content integration, AI-powered lip sync supporting over 90 languages with cultural nuances, combined workflows for automated face swap and lip-sync pipelines, and developer APIs enabling quick integration in apps.
Established industry leaders include Sync.so, Vozo AI, and Gooey AI, recognized for advanced AI-driven solutions enabling realistic mouth movement and speech alignment. HeyGen and 1 More Shot have strengthened positions by integrating real-time rendering and multilingual capabilities. OmniHuman, LipDub AI, and Magic Hour AI advance virtual human creation by combining lip-sync with advanced facial animation. Akool, Everypixel Labs, and Rask AI leverage machine learning to improve synchronization accuracy across languages and accents. Recent industry developments include D-ID’s Video Translate (August 2024), offering free translation, voice cloning, and lip-sync for rapid multilingual content creation, and Panjaya.ai’s BodyTalk (November 2024), delivering natural lip-sync, speech, and gesture synchronization.
Challenges, Limitations, and Technical Hurdles
Despite remarkable progress, significant technical challenges remain. Language and accent variability poses substantial obstacles — AI models trained primarily on English can struggle with languages featuring tonal structures like Mandarin Chinese, or complex phoneme combinations in Indian languages. The phonetic structures of different languages are fundamentally different, requiring careful model training on diverse linguistic datasets.
Realism versus performance remains a critical trade-off. Real-time lip-syncing can achieve high realism but demands GPU-intensive calculations, particularly for real-time rendering. Finding the right balance between performance and visual fidelity is essential, especially in VR/AR and mobile applications where computational resources are limited. Emotional synchronization adds another layer of complexity — facial motion changes dramatically based on emotion in speech, yet most AI models struggle to recognize and imitate nuances like smiling during conversation, sarcasm, or sadness.
Practical production challenges extend beyond pure technology. Current AI lip-sync workflows require a separate video track for each translated language, unlike traditional dubbing workflows that use a single video track with multiple audio tracks. This represents a significant operational shift for media companies not currently equipped to manage high-volume video stream production. Legal uncertainties cloud adoption at scale — media companies often have rights to alter audio tracks but face explicit prohibitions on changing video itself, requiring special legal consent. Pending AI regulation and decisions from actors’ guilds create uncertainty about when and how AI lip-syncing can be used in large-scale professional productions.
Technical limitations persist even in state-of-the-art models. Most tools perform best with single speakers facing the camera directly. The technology falters and produces “misgenerations” when multiple speakers appear on screen or when speakers are not facing forward. Profile views and angled speakers present particular challenges — lip sync breaks when speakers are at extreme angles or moving dynamically. Dynamic motion scenarios like laughing, shifting weight, or changing facial expressions expose AI limitations. Real-world lighting variations, occlusions (like facial hair or piercings), and non-speaking faces reduce accuracy. For multi-speaker scenarios, manual assignment of voices to specific faces is often required for optimal results.
Deepfake concerns and misuse represent a critical ethical dimension. Lip sync technology can be weaponized for malicious purposes, including spreading misinformation, creating fake news, or defaming individuals. The technology’s capacity to seamlessly manipulate audio and video raises questions about the authenticity of visual evidence in the digital age. Deepfake videos pose serious threats to personal privacy by creating explicit or compromising content without consent, potentially violating privacy rights and ruining reputations. Detection of lip-sync deepfakes has become increasingly important — research has shown that sophisticated detection models like LIPINC-V2 can achieve 99% AUC (Area Under Curve) on unseen datasets, detecting manipulated content even under heavy compression. However, this arms race between generation and detection technologies continues to escalate.
Emerging Trends and Future Outlook for 2025 and Beyond
The trajectory of lip sync technology in 2025 points toward increasingly sophisticated and integrated capabilities. Real-time generation and interaction is gaining momentum, with platforms moving beyond pre-rendered videos to enable live, interactive AI-powered experiences. This will revolutionize live streaming, gaming, and virtual events. Personalization at scale represents another critical trend — AI will enable creation of videos dynamically tailored to individual viewers in real-time, blurring lines between mass media and one-to-one communication.
Integration with other AI modalities is reshaping the production pipeline. Combining lip sync with AI-generated music, voiceovers, interactive scripts, and background sounds is enabling fully automated, end-to-end content creation. The broader generative AI market that encompasses video synthesis was valued at approximately $10.8 billion in 2023 and is projected to reach $110.7 billion by 2030, showcasing extraordinary growth. The generative AI video market specifically is experiencing a CAGR exceeding 30% through 2027. By 2026, synthetic media generated by AI will be indistinguishable from real media for most people, according to Gartner predictions.
Multimodal models that process and generate content based on richer understanding of various data types are advancing rapidly. Models like Vidu Q1 support reference-to-video generation using up to 7 images, dynamic anime video creation, and AI-generated background music and sound effects. Efficiency improvements are democratizing the technology — development of more efficient and accessible AI models optimized for mobile devices and edge computing will enable broader access. Interoperability between different AI tools will enable creators to assemble custom workflows best suited to their projects.
How to Choose and Use Lip Sync AI: A Practical Guide
For individual content creators with budgets of free to $30/month, priorities include ease of use, watermark-free output, and quick social media content creation. Recommended platforms include HeyGen for avatars and efficiency, Veed.io for casual use, and Magic Hour for face swap features. Small businesses and startups with $30–$100/month budgets should prioritize brand consistency, multi-use cases, and collaboration features, making Vozo AI, HeyGen, and Synthesia strong choices. Enterprise organizations with $300+/month and custom budget requirements need security compliance, API access, and LMS integration — Synthesia, Tavus, and Sync.so offer these capabilities.
When evaluating tools, several key factors matter. Accuracy metrics should be examined — does the tool publish LSE-D or other synchronization scores? Language support determines reach — does it support your target markets? Face handling matters for quality — can it process side angles and dynamic movement? Multi-speaker capability is essential for complex content. Audio control determines flexibility — can you use your own voiceovers or only platform voices? Real-time performance becomes critical for live streaming applications. API availability enables custom integrations for developers and studios. Cost structure should align with your production frequency — pay-as-you-go, subscriptions, or enterprise licensing.
Conclusion: The AI Lip Sync Revolution Is Here
Lip sync AI has evolved from a novelty technology into an essential tool reshaping content creation, entertainment production, and global communication. The USD 5.76 billion market projection by 2034 and 17.8% CAGR growth reflect genuine industry demand and accelerating adoption. What once required hours of expert animation, significant budgets for professional dubbing, or impossible limitations for independent creators is now accessible, affordable, and achievable in minutes.
The technology enables creators to amplify their reach across languages without re-recording, helps educators connect with global audiences, allows brands to localize marketing at scale, and democratizes filmmaking by removing production barriers. For those serious about content creation in 2025, understanding and leveraging lip sync AI isn’t optional — it’s a competitive necessity. The platforms, tools, and technologies exist today. The question is no longer “can we make any character talk in any language?” — it’s “how quickly can we master this technology to tell better stories and reach bigger audiences?”
As ethical safeguards, regulatory frameworks, and detection technologies mature alongside the generative capabilities, responsible creators have an opportunity to lead the industry by prioritizing transparency, consent, and authenticity in how they deploy these powerful tools.
Read More:Can You Monetize AI-Generated Video on YouTube? (2025 Rules)
Source: K2Think.in — India’s AI Reasoning Insight Platform.