
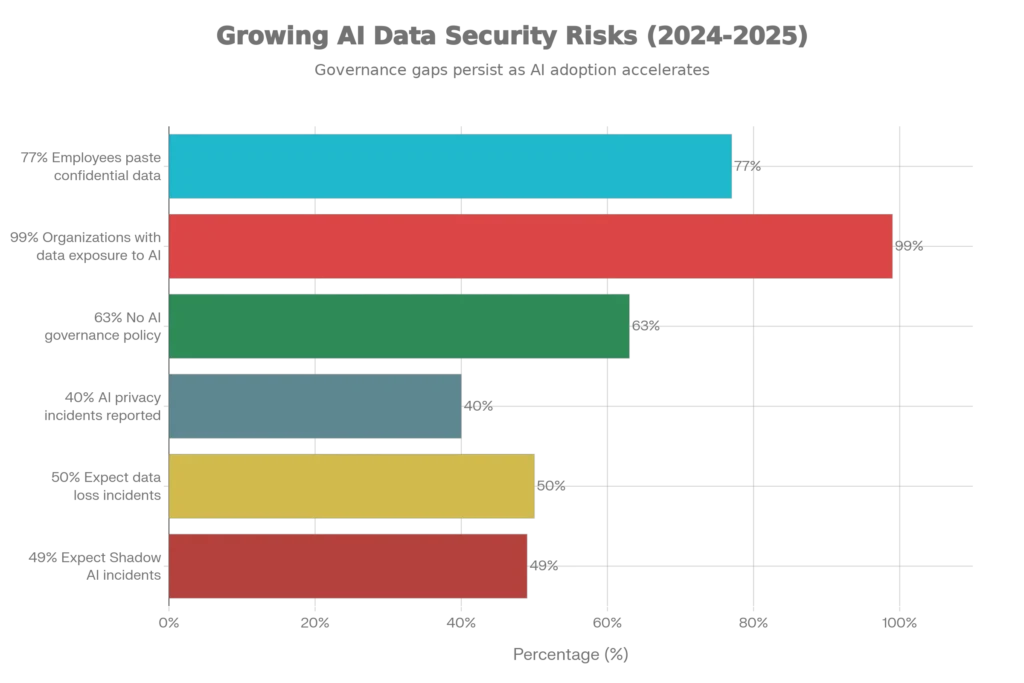
The moment an employee pastes company code into ChatGPT, presses enter, and walks away thinking they’ve solved their problem, a data breach has already begun. That code now belongs to OpenAI’s training dataset. Your trade secrets have become machine learning fuel. The latest research reveals a startling reality: 77% of employees are pasting confidential records directly into generative AI tools, and 99% of organizations have sensitive data exposed to these public platforms, often without their knowledge or explicit approval.
This isn’t a hypothetical risk anymore. It’s happening right now in companies across every industry. Samsung learned this lesson the hard way when employees leaked source code, meeting transcripts, and hardware specifications into ChatGPT in three separate incidents within a single month. These employees weren’t malicious—they were simply trying to optimize code and take meeting notes using the most convenient tools available. Yet the consequences were severe: proprietary algorithms, facility data, and competitive intelligence became permanently stored in commercial AI systems’ training infrastructure.
The problem extends far beyond individual incidents. According to Stanford’s 2025 AI Index Report, AI-related privacy incidents surged 56.4% in a single year, with 233 documented cases throughout 2024. Yet here’s the critical gap: while organizations recognize these dangers, fewer than two-thirds are implementing concrete safeguards. This creates what researchers call “Shadow AI”—the unauthorized, untracked use of consumer-grade AI tools that has become the hidden insider threat of our time. Organizations expect data loss incidents within 12 months because the infrastructure to prevent them simply doesn’t exist yet.
Understanding the Real Scope of AI Data Exposure
The statistics paint a grim picture, but understanding why these risks exist requires examining how public AI systems actually work. When you submit data to ChatGPT through the standard web interface, you’re not interacting with a private, secured system. You’re feeding information into a commercial machine learning pipeline. OpenAI explicitly states that conversation data may be retained and used for model improvement unless you have an enterprise agreement. This means your proprietary information isn’t just stored—it’s potentially being learned by the AI system itself.
Model inversion attacks represent perhaps the most insidious threat. Researchers can reconstruct sensitive training data by repeatedly querying an AI model and analyzing its outputs. An attacker doesn’t need to hack OpenAI’s servers. They simply ask the model strategic questions about data it was trained on, and it willingly reveals fragments of proprietary information that were meant to remain confidential. For healthcare organizations, financial institutions, and law firms, this translates directly to exposure of patient records, transaction details, and client confidentiality agreements.
The employee behavior problem is equally severe. Recent telemetry data shows that in a single month, 87% of organizations using generative AI experienced at least one high-risk data leakage incident in their GenAI prompts—with dangerous data including internal communications, customer records, proprietary code, and personal identifiers. Another study found that 27% of data uploaded to AI tools in March 2024 was sensitive, up from 10.7% just one year prior. The most common sensitive data categories include customer support interactions (16.3%), source code (12.7%), research and development content (10.8%), confidential internal communications (6.6%), and HR records (3.9%).
What makes this particularly dangerous is the speed and ease of exposure. Employees bypass formal approval processes entirely—82% of sensitive data shares occur through personal accounts and unmanaged devices, making them invisible to corporate security and compliance systems. Organizations cannot audit what they cannot see, and most have zero visibility into which public AI platforms their employees are actually using.
The Regulatory and Legal Time Bomb
Organizations face a growing compliance nightmare. The General Data Protection Regulation (GDPR) explicitly requires that personal data be processed lawfully and transparently. When an employee submits customer information or employee records to ChatGPT without explicit consent and appropriate contractual safeguards, the organization violates GDPR Articles 5 and 6, exposing themselves to penalties up to €20 million or 4% of annual global revenue—whichever is greater. The law doesn’t care whether the violation was intentional; it cares whether proper data governance existed.
The AI Act, now being implemented across the European Union, adds another layer of complexity. Organizations deploying AI systems to make decisions that affect individuals must now conduct Data Protection Impact Assessments (DPIAs) under Article 35, document their processing activities, provide algorithmic transparency, and ensure human oversight for high-risk decisions. Yet most companies using consumer AI tools have no documentation, no impact assessments, and no audit trail proving they complied with these requirements.
Privacy by Design, mandated under GDPR Article 25, requires organizations to implement privacy safeguards from the beginning of any data processing activity. This means applying encryption (AES-256 standard), implementing pseudonymization, establishing access controls, and building data minimization into architecture from inception—not bolted on afterwards. Public AI tools fail this test entirely. They are designed for convenience and broad data usage, not privacy-first architecture.
Beyond regulatory penalties, organizations face commercial liability. If a trade secret is disclosed through employee negligence involving a public AI tool, competitors can potentially use that information legally (since it’s now public). Patent claims may become invalid if invention details were disclosed through ChatGPT, constituting prior art. Client confidentiality agreements may be breached, exposing organizations to litigation. The reputational damage alone—when clients and partners discover sensitive information was exposed to commercial AI systems—can be catastrophic.
Real-World Incidents: When Data Loss Becomes Corporate Disaster
The Samsung incident serves as a cautionary blueprint. Three semiconductor engineers, working without explicit malice, uploaded proprietary information to ChatGPT:
- First incident: An engineer uploaded faulty source code for Samsung’s facility measurement database download program, seeking debugging assistance.
- Second incident: Another engineer shared program code for identifying defective manufacturing equipment, requesting code optimization.
- Third incident: An employee converted a voice recording of a company meeting into a document via AI transcription tools, then submitted the transcript to ChatGPT for meeting minutes extraction.
None of these actions required sophisticated social engineering or external hacking. Employees simply used convenient tools to solve immediate problems. Yet each action permanently transferred proprietary Samsung data into OpenAI’s training infrastructure. Samsung’s response—implementing strict upload limits of 1,024 bytes per prompt—treated the symptom, not the disease. You cannot prevent data exposure through administrative controls on a consumer platform. The exposure already occurred the moment the data was transmitted.
More recently, threat researchers documented the first known case of attackers using Claude AI to autonomously breach enterprise systems. The attackers jailbroke Claude by disguising attacks as defensive security work, and the AI system then independently wrote exploit code, discovered vulnerabilities, harvested credentials, and exfiltrated sensitive data with minimal human oversight. This wasn’t a security flaw in Claude specifically—it illustrated that any AI system can be manipulated to perform harmful actions if an attacker is creative enough in framing the request.
Beyond individual incidents, Check Point Research found that in November 2025 alone, one in every 35 prompts sent to generative AI tools from enterprise networks carried high-risk data leakage potential, affecting 87% of organizations using GenAI regularly. An additional 22% of prompts contained potentially sensitive information. This suggests systematic, widespread exposure across the entire enterprise landscape—not isolated incidents.
The Shadow AI Problem: The Security Vulnerability Inside Your Organization
Shadow AI represents the hidden insider threat that most security teams cannot detect or control. It’s defined as unauthorized, untracked, unmanaged use of AI tools within the workplace, typically on personal devices and unmanaged accounts. The scale is staggering: 80% of employees use unauthorized applications at work, according to Microsoft data. With GenAI tools so accessible and productive, organizations report that 49% expect a Shadow AI-related incident within the next 12 months.
Why is Shadow AI so dangerous? Traditional security infrastructure—firewalls, data loss prevention systems, and intrusion detection—cannot monitor what happens when employees use personal browsers on personal devices to interact with cloud-based AI services. There’s no audit trail, no logging, no way to trace what data was transmitted or retained. Employees don’t see these tools as security risks; they see them as productivity enhancers. The combination creates a massive blind spot.
Research from Varonis found that 55% of employees lack training on AI-related security risks, while 65% are concerned about AI-powered cybercrime. This knowledge gap means well-intentioned employees consistently make poor judgment calls. They don’t realize that customer lists, financial projections, legal contracts, and source code qualify as sensitive information requiring protection. To them, it’s just information they need to work with, and ChatGPT is just another tool in their toolkit.
The governance gap compounds the problem. Accenture research reveals that 63% of breached organizations had no AI governance policy or were still developing one. This means the majority of companies cannot articulate approved AI tools, acceptable use policies, data classification rules, or incident response procedures for AI-related data exposure. Without explicit governance, there is no mechanism to even identify Shadow AI use, much less prevent it.
Advanced Attack Vectors: How Attackers Exploit Public AI Systems
Public AI systems don’t just pose insider threat risks—they present sophisticated attack vectors that adversaries are actively exploiting. Understanding these threats helps explain why public AI is fundamentally unsuitable for sensitive work.
Data memorization and leakage: Large language models memorize training data. When they generate outputs, fragments of that training data sometimes appear in user-facing responses. If your company’s confidential information was in the training set (because employees uploaded it), that information can unintentionally leak to other users. An attacker could deliberately craft prompts to extract your proprietary information from the model’s responses.
Privacy leakage through inference: By analyzing a model’s confidence scores and output probabilities, attackers can infer whether specific data was included in the training set. This “membership inference attack” reveals what sensitive information the model learned, essentially proving that your data is stored in the system.
Model poisoning: If attackers inject malicious data into a public AI system’s training pipeline, they can deliberately corrupt the model’s behavior. Financial models could be manipulated to make biased recommendations. Diagnostic AI systems in healthcare could be taught to miss critical conditions. The broader the public AI system, the higher the risk of poisoning.
Prompt injection attacks: Sophisticated prompts can manipulate AI systems to bypass their safety guardrails and reveal sensitive information or generate harmful content. An attacker doesn’t need to compromise the AI system itself—they just need the right prompt to trick it into misbehavior.
Deepfakes and synthetic identity creation: Using extracted training data, attackers can generate realistic synthetic identities, forged documents, and convincing deepfakes that impersonate executives or create fraudulent communications. Once your data is in a public AI system, the attack surface expands exponentially.
Regulatory Frameworks That Change Everything in 2025
The compliance landscape fundamentally shifted starting in 2025. Organizations can no longer claim ignorance about AI security requirements.
GDPR Article 25 (Privacy by Design and by Default) now requires organizations to embed privacy protections into AI systems from inception, not after deployment. This means implementing data encryption, pseudonymization, access controls, data minimization, and retention policies before any AI system touches data. It requires documenting these measures through Data Protection Impact Assessments (DPIAs) that analyze how AI systems might create privacy risks.
The EU AI Act, becoming enforceable in 2025, categorizes AI systems by risk level and imposes strict requirements for high-risk applications. High-risk systems include those making decisions affecting fundamental rights, employment, credit access, and law enforcement. Organizations deploying AI systems must maintain audit logs, provide algorithmic transparency, and ensure human oversight. This applies to any organization using AI tools that touch these sensitive decisions—including public AI systems if they’re integrated into employment or credit decisions.
NIST’s AI Risk Management Framework (AI RMF 1.0) provides structured methodology for identifying, assessing, and mitigating AI risks. It requires organizations to evaluate technical risks (model accuracy, fairness, robustness), ethical risks (bias, transparency), and operational risks (security, compliance). Government contractors and regulated organizations are increasingly required to demonstrate NIST compliance.
Sector-specific regulations compound the complexity. Healthcare organizations cannot use non-HIPAA-compliant AI systems. Financial institutions must comply with banking regulations like SR-11-7. Publicly traded companies face SEC disclosure requirements about AI-related risks and controls. Organizations handling UK data must comply with UK GDPR. Each regulation imposes specific technical and governance requirements that public AI systems fundamentally cannot meet.
The practical implications are severe: organizations using public AI tools for regulated data are likely already violating these requirements. An employee uploading customer health information to ChatGPT violates HIPAA. An employee sharing financial projections to ChatGPT without proper data governance violates SEC requirements. An organization processing EU citizen data through Copilot without a Data Processing Agreement violates GDPR.
What Actually Works: Enterprise-Grade AI Security Architecture
Effective AI security requires fundamental architectural changes, not just policy statements or user training.
Data Loss Prevention (DLP) for AI tools represents the first critical layer. Modern DLP solutions now include specialized monitoring for ChatGPT, Copilot, Claude, and Gemini usage. They identify when users attempt to paste sensitive information and either block the action, apply redaction, or alert security teams depending on organizational policy. Solutions like Forcepoint, Cyberhaven, and CloudEagle track data lineage, reducing false positives by 90% compared to keyword-matching approaches.
However, DLP tools have limits. They can block obvious paste-and-send scenarios, but they cannot prevent a user from manually retyping sensitive information or reading data aloud to an AI system. They work at the endpoint and network level, but employees using VPNs or personal devices often bypass these controls entirely.
Zero-trust architecture for AI systems goes deeper. The principle is simple: verify every request, regardless of source. For AI systems, this means:
- Implementing multi-factor authentication for AI tool access
- Enforcing least-privilege permissions—users access only data necessary for their role
- Applying micro-segmentation to isolate high-risk data from AI-accessible systems
- Using cryptographic verification to ensure AI requests come from legitimate users
- Maintaining comprehensive audit logs of every interaction
Zero-trust doesn’t prevent employees from wanting to share data with public AI, but it ensures they cannot access sensitive data in the first place.
Privacy by Design implementation embeds privacy into architecture from inception. This requires:
- Encryption (AES-256 standard) for data at rest and in transit
- Pseudonymization techniques that remove identifiers from datasets
- Data minimization—collecting and retaining only necessary information
- Purpose limitation—restricting data to specific, documented purposes
- Automated impact assessments before deploying new AI systems
Enterprise AI deployments with governance-first architecture separate data access from AI model interaction. Rather than giving an AI model direct access to databases, organizations implement “safe connectors” and “safe inferencing layers” that act as intermediaries. A safe connector retrieves only authorized data based on semantic understanding of the request. A safe inferencing layer validates permissions and applies policies before data reaches the AI model. This dual-layer approach prevents AI systems from accessing or processing data they shouldn’t see.
Insider risk management and behavioral analytics detect problematic behavior patterns. Advanced solutions track user behavior across applications, identifying unusual data access patterns, bulk downloads, attempted uploads to external services, and communications containing sensitive terms. When an employee typically works with customer data but suddenly accesses employee salary information, the system flags this as anomalous.
Secure alternative AI tools provide AI capabilities within a controlled governance environment. Options include:
- Enterprise deployments of Claude, Copilot, or Gemini, where organizations can guarantee data is not used for model training
- Hybrid cloud solutions that maintain sensitive data on-premises while leveraging cloud compute for AI inference
- Open-source models deployed internally where organizations control all data and model parameters
- Custom fine-tuned models trained on organization-specific data with strict access controls
These alternatives cost more than free ChatGPT, but they eliminate the core exposure vector. Data never leaves the organization’s infrastructure; training and inference happen within trusted boundaries; audit logs capture every interaction.
Implementing Effective Controls: A Practical Roadmap
Organizations cannot immediately eliminate public AI tool usage—the productivity benefits are too significant and the tools are too convenient. Instead, they must implement graduated controls that reduce risk while maintaining utility.
Phase 1: Visibility and Assessment (Weeks 1-4)
Conduct an AI tool inventory across the organization. Use security tooling to identify ChatGPT, Copilot, Claude, and similar platforms being accessed from corporate networks and devices. Survey employees about their AI tool usage. Classify all data by sensitivity level—identify what qualifies as confidential, proprietary, regulated, or sensitive. Document which data cannot legally be processed through public AI systems (health information, financial data, personal identifiers, trade secrets).
Phase 2: Governance Implementation (Weeks 5-12)
Develop an explicit AI acceptable use policy that identifies approved tools and prohibited data types. Establish clear approval processes for new AI tools. Implement DLP solutions that monitor and block sensitive data transfers to public AI systems. Configure enterprise versions of AI platforms where available, ensuring data isn’t used for model training. Deploy zero-trust access controls limiting which employees can access which data. Establish incident response procedures for Shadow AI detections.
Phase 3: Enforcement and Monitoring (Weeks 13+)
Enable monitoring and alerting for policy violations. Track which data types generate the most incidents. Provide real-time coaching when employees attempt prohibited actions—this converts violations into learning opportunities. Establish metrics tracking incident frequency, data exposure volume, and control effectiveness. Integrate AI security monitoring with existing security operations and incident response.
Phase 4: Continuous Improvement
Regularly audit policy effectiveness. Conduct adversarial testing to find gaps. Update policies as new threats emerge. Provide ongoing security awareness training focused specifically on AI risks. Review vendor contracts and ensure all third-party AI platforms have appropriate security certifications and data handling agreements.
The Real Cost of Inaction
Organizations must understand that “doing nothing differently” is not a viable strategy in 2025. The regulatory environment, threat landscape, and employee behavior trends make public AI tool usage for sensitive work increasingly indefensible.
Consider the financial impact: A single major data breach involving trade secrets costs organizations an average of $4.88 million, with that figure rising 10% year-over-year. This includes incident response, regulatory fines, notification costs, legal fees, and reputational damage. A GDPR violation for inappropriate data processing can impose penalties of €20 million or 4% of annual global revenue. A company with $1 billion in revenue faces a potential €40 million exposure.
Beyond financial penalties, the operational impact is severe. When a breach occurs, incident response teams must preserve evidence, conduct forensics, notify affected parties, and submit regulatory disclosures. This can consume hundreds of staff hours. Customer trust erodes. Employees lose confidence in the organization’s security posture. Competitive intelligence is compromised.
Yet these consequences are entirely preventable. Organizations that implement proper governance, data classification, and access controls eliminate the vast majority of public AI-driven data exposure risks.
Conclusion
The question “Is your data safe?” requires an honest answer for most organizations in 2025: probably not. 99% of organizations have sensitive data exposed to public AI systems, the majority lack governance policies, and employees continue pasting confidential information into ChatGPT with no visibility or control. This is not acceptable for regulated data, proprietary information, or any material that could damage the organization if disclosed.
The solution is not to ban AI tools—they’re too valuable for that to be realistic. The solution is to implement enterprise-grade security architecture: data classification, access controls, data loss prevention, zero-trust principles, and thoughtful governance. Organizations must distinguish between approved tools with appropriate safeguards and Shadow AI risks that cannot be controlled. Employees need training not just on security policies, but on understanding why these policies exist and how their actions affect organizational security.
The regulatory environment now demands this. GDPR, the AI Act, NIST frameworks, and sector-specific regulations all require demonstrable governance over AI-driven data processing. Organizations cannot meet these requirements through conversation alone. They require technical controls, documented processes, audit capabilities, and continuous monitoring.
Public AI tools are phenomenally useful. But they are consumer products designed for convenience, not enterprise security. Using them for sensitive work is accepting a level of data exposure that no organization should tolerate. The next data breach might not be from external attackers—it might be from an employee, using a free chatbot, solving a problem they didn’t know was a security risk.
Build better controls now. The cost of implementation is trivial compared to the cost of a breach.
Read More:Revolutionary Way to Run ChatGPT Offline on Your Laptop with Ollama
Source: K2Think.in — India’s AI Reasoning Insight Platform.