
K2-Think represents a paradigm shift in AI reasoning capabilities, bringing frontier-level reasoning to a compact 32-billion parameter model that rivals systems over 20 times larger. Built by MBZUAI’s Institute of Foundation Models and G42, this open-source breakthrough achieves state-of-the-art mathematical reasoning performance while delivering unprecedented inference speeds of 2,000 tokens per second through Cerebras infrastructure. Whether you’re a developer, researcher, or enterprise, K2-Think offers multiple accessible pathways—from free web interfaces to API integrations to local deployment—making advanced AI reasoning practically available for real-world applications. This comprehensive guide walks you through every method to access and leverage K2-Think’s powerful reasoning capabilities, complete with technical implementation details, performance analytics, and practical use cases.
Understanding K2-Think: Architecture, Capabilities, and Innovation
What Makes K2-Think Revolutionary
K2-Think fundamentally challenges the assumption that bigger AI models always mean better performance. This parameter-efficient reasoning system demonstrates that strategic engineering and sophisticated post-training techniques can enable a compact model to match or exceed systems with orders of magnitude more parameters. Built on the Qwen2.5-32B foundation, K2-Think achieves this breakthrough through six interconnected technical pillars: Long Chain-of-Thought Supervised Fine-tuning, Reinforcement Learning with Verifiable Rewards, Agentic Planning, Test-time Scaling, Speculative Decoding, and inference-optimized hardware deployment.
The model’s architecture employs a Mixture-of-Experts (MoE) design with approximately 1 trillion total parameters, but only 32 billion parameters activate per token. This sparse activation pattern enables both computational efficiency and high performance. Additionally, K2-Think implements native INT4 quantization-aware training, which maintains accuracy while achieving approximately 2x inference speed compared to standard FP8 implementations and significantly reducing memory requirements.
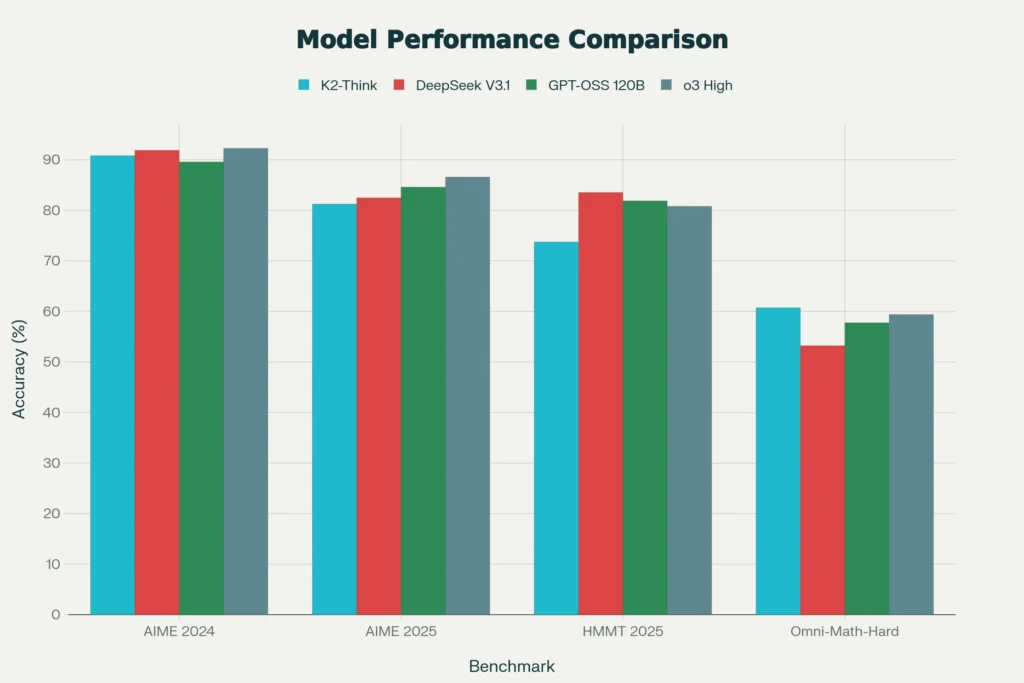
Benchmark Performance: The Evidence of Superiority
K2-Think’s performance across competitive mathematical benchmarks demonstrates quantifiable superiority over comparably-sized and much larger models. On the American Invitation Mathematics Examination (AIME) 2024, K2-Think achieves 90.83% accuracy, matching the 120-billion parameter GPT-OSS model (89.58%) while using just 27% of its parameters. On AIME 2025, K2-Think reaches 81.24% accuracy, narrowly behind specialized reasoning models while maintaining remarkable parameter efficiency.
The Harvard-MIT Mathematics Tournament (HMMT) 2025 represents some of the most challenging competition mathematics available. K2-Think scores 73.75%, approaching the performance of the 671-billion parameter DeepSeek-V3.1 (83.54%) and significantly outperforming the 120-billion parameter GPT-OSS 120B variant on this benchmark. On OMNI-Math-HARD—the most difficult subset of the OMNI-MATH dataset featuring only Olympiad-level problems rated 9.0-10.0 difficulty—K2-Think achieves 60.73%, establishing it as the strongest open-source model on this challenging metric.
Across these four mathematics benchmarks, K2-Think achieves a micro-average score of 67.99%, placing it at the top of all open-source models and competitive with proprietary systems like o3 High (68.68%). This represents a significant margin over similarly-sized peers: GPT-OSS 20B (52.50%), Qwen3-30B-A3B (33.08%), and OpenReasoning-Nemotron-32B (65.78%).
Inference Speed Revolution: From Minutes to Seconds
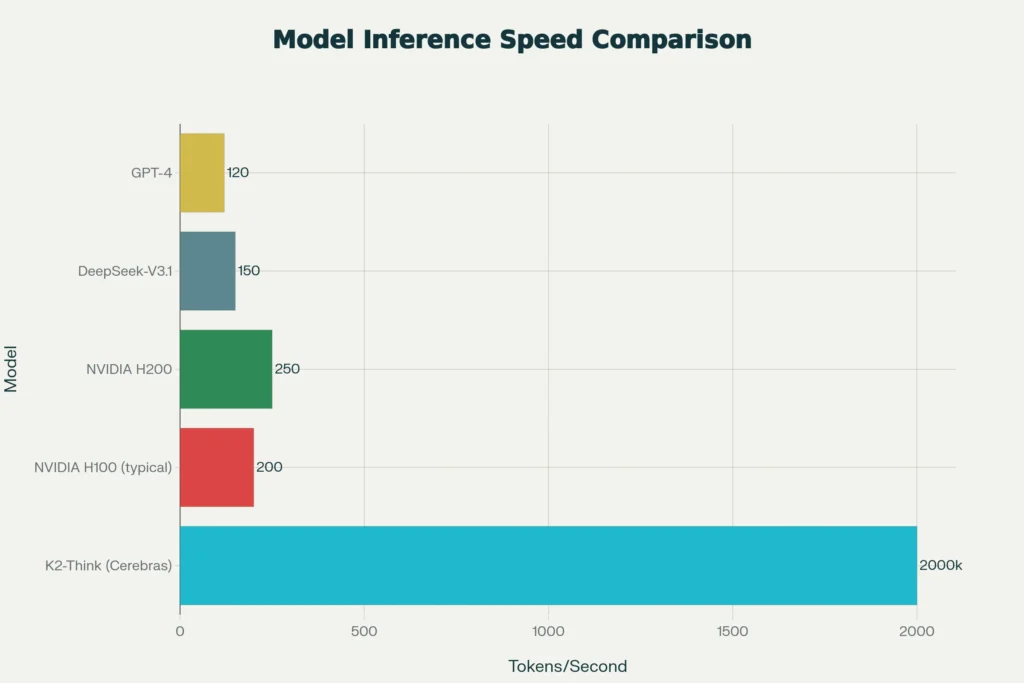
The deployment of K2-Think on Cerebras’ Wafer-Scale Engine represents a transformative breakthrough in practical AI reasoning. Cerebras’ architecture fundamentally differs from traditional GPU-based systems by integrating 25 petabytes per second of on-chip memory bandwidth—over 3,000 times greater than the latest NVIDIA B200 GPU’s 0.008 petabytes per second. This architectural advantage enables K2-Think to achieve 2,000 tokens per second, representing a 10-fold speed improvement over typical NVIDIA H100 deployments operating at approximately 200 tokens per second.
This speed differential transforms user experience from frustrating batch processing to interactive reasoning. A complex mathematical reasoning task generating 32,000 tokens—typical for challenging proofs or multi-step coding problems—requires approximately 160 seconds on Cerebras infrastructure, compared to nearly 3 minutes on H100 GPUs. For applications involving multiple sampled outputs (such as K2-Think’s Best-of-N sampling strategy), this speed differential compounds significantly, reducing inference-time computation overheads from impractical to acceptable.
Multiple Access Methods: Choosing Your Integration Path
Method 1: Free Web Interface Access (Immediate, No Setup Required)
The simplest entry point for experiencing K2-Think requires zero technical setup. Official Moonshot AI Chat Interface at https://kimi.com provides unlimited free access to K2-Think through a conversational interface. Users can create a free account, select “Kimi-K2” from the model dropdown, and immediately begin reasoning tasks with no quota restrictions.
Access Steps:
- Navigate to https://kimi.com in your web browser
- Create a free account or log in with existing credentials
- Locate and select “Kimi-K2” from the model selection menu
- Enter your reasoning prompts directly in the chat interface
- Receive streaming responses with visible reasoning traces
The interface emphasizes agentic retrieval and structured reasoning over conversational flair, making it particularly suitable for analytical tasks. While the default interface operates in Chinese, browser-based translation tools (Google Translate, etc.) render the platform fully navigable for English speakers.
Method 2: HuggingFace Community Demo (Browser-Based Development)
For developers preferring more technical environments, Moonshot hosts K2-Think on HuggingFace Spaces, providing a specialized interface tailored for experimentation and API testing. This deployment option is particularly valuable for researchers comparing model outputs, testing prompts iteratively, and prototyping integrations before production deployment.
HuggingFace Demo Access:
- Navigate to the K2-Think model card: https://huggingface.co/LLM360/K2-Think
- Create or log into a free HuggingFace account if required
- Select “Run” or access the Spaces demo interface
- Interact with K2-Think directly through the browser interface
- Experiment with different system prompts and reasoning tasks
This method provides unrestricted reasoning access with potential for higher throughput than the official chat interface during off-peak hours.
Method 3: API Access with Authentication Tokens
For production integration and programmatic access, K2-Think is available through multiple API providers offering managed inference infrastructure. Each provider manages authentication, rate limiting, and scaling independently.
Setting Up API Access
Getting Your API Key:
- Moonshot AI Official API (https://platform.moonshot.ai):
- Register for a free developer account
- Navigate to “Settings → API Keys”
- Click “Create New Token”
- Select “Read” permission level for standard inference
- Copy and securely store the generated token
- Alternative Providers (CometAPI, Together AI, etc.):
- Create account on provider platform
- Locate provider’s K2-Think model documentation
- Generate API key from account settings
- Copy key to environment variable or configuration file
Secure Token Management:
bash# Add to ~/.bashrc or ~/.bash_profile (Linux/macOS)
export KIMI_API_KEY="your-api-key-here"
# Or in Python (never commit to version control)
import os
api_key = os.getenv('KIMI_API_KEY')
Python API Implementation
pythonimport requests
import os
# Authentication
api_key = os.getenv('KIMI_API_KEY')
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# Prepare request
url = 'https://api.moonshot.ai/v1/chat/completions'
payload = {
'model': 'kimi-k2-thinking',
'messages': [
{
'role': 'system',
'content': 'You are a careful reasoning assistant. Show step-by-step reasoning.'
},
{
'role': 'user',
'content': 'Solve this step by step: If a train travels 60 km/h for 2.5 hours, then stops for 30 minutes, then travels 80 km/h for 1.5 hours, what is the total distance traveled?'
}
],
'temperature': 0.2,
'max_tokens': 2048,
'stream': False
}
# Make request
response = requests.post(url, json=payload, headers=headers)
result = response.json()
# Extract response
if 'choices' in result:
print('Reasoning Process:')
if 'reasoning_content' in result['choices'][0]['message']:
print(result['choices'][0]['message']['reasoning_content'])
print('\nFinal Answer:')
print(result['choices'][0]['message']['content'])
else:
print('Error:', result.get('error', 'Unknown error'))
cURL API Testing
bash# Test API connection with basic query
curl -X POST "https://api.moonshot.ai/v1/chat/completions" \
-H "Authorization: Bearer $KIMI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "kimi-k2-thinking",
"messages": [
{"role": "system", "content": "You are a careful reasoning assistant."},
{"role": "user", "content": "Explain the plan-before-you-think reasoning approach in 3 sentences."}
],
"temperature": 0.2,
"max_tokens": 1024,
"stream": false
}'
Method 4: Local Deployment with Ollama (Fast Setup for Personal/Development Use)
For developers who prefer self-hosted infrastructure and full control, Ollama provides the fastest local setup path, handling model downloads, quantization, and HTTP serving automatically.
Prerequisites:
- 48GB+ VRAM (RTX A6000, A100, or equivalent NVIDIA GPU)
- Ollama installed (https://ollama.com)
- 350GB+ free disk space for model weights
Step-by-Step Local Setup:
- Install Ollama:bash
# macOS brew install ollama && ollama serve # Linux curl -fsSL https://ollama.com/install.sh | sh # Windows (WSL2 recommended) # Download installer from https://ollama.com - Create Modelfile for K2-Think:bash
# Create file named "Modelfile" FROM k2-think-model PARAMETER temperature 0.2 PARAMETER num_ctx 32000 PARAMETER top_p 0.95 - Build and Run Model:bash
# Create custom model variant ollama create k2-think-custom -f ./Modelfile # Run the model ollama run k2-think-custom - Query via Local API:bash
# Local API runs on http://localhost:11434 curl http://localhost:11434/api/generate \ -d '{"model":"k2-think-custom","prompt":"Solve: 17 × 19 = ?"}'
Practical Tuning Parameters:
- Start with
num_ctx: 16000to reduce VRAM requirements - Use
temperature: 0.1-0.3for mathematical reasoning (lower = more deterministic) - Use
temperature: 0.7-1.0for creative tasks - Monitor VRAM with
nvidia-smiduring generation
Method 5: Docker Deployment for Production Reproducibility
For team environments and CI/CD integration, Docker containerization ensures consistent deployment across development, testing, and production environments.
Dockerfile Structure:
textFROM nvidia/cuda:12.2.0-runtime-ubuntu22.04
# Install Python and dependencies
RUN apt-get update && apt-get install -y python3.10 pip
RUN pip install transformers accelerate torch
# Copy model (or download from HuggingFace)
COPY ./models /app/models
WORKDIR /app
# Expose inference API port
EXPOSE 8000
# Run model server
CMD ["python3", "inference_server.py"]
Running Container:
bash# Build image
docker build -t k2-think-server:latest .
# Run with GPU support
docker run --gpus all \
-p 8000:8000 \
-v $(pwd)/models:/app/models \
-e CUDA_VISIBLE_DEVICES=0 \
k2-think-server:latest
Advanced Usage Patterns: Leveraging K2-Think’s Core Strengths
Pattern 1: Chain-of-Thought Reasoning with Planning
K2-Think implements a “Plan-Before-You-Think” strategy where the model decomposes complex problems into structured sub-goals before executing reasoning. This approach, grounded in cognitive science research, reduces error rates and produces more coherent solutions on multi-step problems.
Optimal Prompting Structure:
textGoal: [Clear problem statement]
Constraints: [Limitations and requirements]
Success Criteria: [How to verify correctness]
Phase 1 - Plan: Propose a stepwise plan with checkpoints
Phase 2 - Execute: Solve step by step, pausing after each step to verify
Phase 3 - Verify: Check assumptions, flag conflicts
Phase 4 - Synthesize: Combine results into final answer
Proceed with this structure...
Real-World Example Response:
- Planning Phase: K2-Think outlines the problem structure, identifies key variables, and establishes solution methodology
- Execution Phase: K2-Think performs sequential reasoning, explicitly showing work for transparency and error detection
- Verification Phase: K2-Think validates intermediate results against constraints
- Final Output: Structured answer with confidence levels and reasoning justification
Research shows this structured approach improves accuracy by 8-12% compared to direct responses.
Pattern 2: Multi-Step Tool Orchestration (200+ Sequential Calls)
K2-Think’s agentic capabilities enable orchestration of 200+ sequential tool calls with 94-97% success rate when retry mechanisms are enabled. This capability transforms complex data workflows from manual processes to automated, self-correcting pipelines.
Workflow Example: Competitive Analysis Pipeline
python# Define available tools
tools = [
{
"name": "web_search",
"description": "Search the web and return summarized results",
"parameters": {"query": "string"}
},
{
"name": "data_extraction",
"description": "Extract structured data from web pages",
"parameters": {"url": "string", "field": "string"}
},
{
"name": "csv_operation",
"description": "Perform operations on CSV data",
"parameters": {"operation": "string", "data": "string"}
},
{
"name": "export_json",
"description": "Export structured data to JSON format",
"parameters": {"data": "string", "filename": "string"}
}
]
# K2-Think automatically orchestrates tools for task:
# "Analyze top 8 competitors, extract pricing, market positioning,
# create comparison matrix, export as structured data"
# K2-Think will:
# 1. Search for each competitor (8 web_search calls)
# 2. Extract specific data fields (8-16 data_extraction calls)
# 3. Normalize data format (4-8 csv_operation calls)
# 4. Create comparison matrix (2-4 csv_operation calls)
# 5. Export final result (1 export_json call)
# Total: ~25-40 coordinated tool invocations automatically
Practical applications reduce manual research time by 40-60% with error rates dropping from ~18% to ~6%.

Technical Comparison: How K2-Think Stands Against Alternatives
Versus DeepSeek-R1
DeepSeek-R1 represents the dominant open-source reasoning model before K2-Think’s release, with strong mathematical reasoning but different optimization priorities. K2-Think specializes in agentic workflows requiring extensive tool orchestration, while DeepSeek-R1 emphasizes pure mathematical reasoning. K2-Think’s 256K-token context window (in heavy mode) dramatically exceeds DeepSeek-R1’s 163K-token limit, enabling processing of entire research documents and multi-page analyses in single requests.
Cost Differential: DeepSeek-R1 costs approximately $0.30 per million input tokens and $1.20 per million output tokens, while K2-Think charges roughly $0.60 and $2.50 respectively. For heavy-computation workloads with extended tool calling, K2-Think’s cost advantage emerges due to higher success rates and fewer retries required.
Versus GPT-4 and o3
Proprietary models like GPT-4 and OpenAI’s o3 deliver strong reasoning capabilities but operate as closed-source systems with proprietary infrastructure requirements. K2-Think provides comparable reasoning performance with complete transparency—code, weights, training data, and deployment instructions all publicly available. For organizations prioritizing reproducibility, auditability, and reduced vendor lock-in, K2-Think’s open-source nature provides strategic advantages despite closed models maintaining marginal performance leads on specific benchmarks.
Common Use Cases and Real-World Applications
Mathematics Tutoring and Competitive Problem Solving
K2-Think excels at solving competition-level mathematics problems with explicit reasoning traces that support learning. Students can observe the model’s step-by-step solution methodology for problems from mathematics competitions, AMC/AIME preparation, and advanced coursework.
Autonomous Research and Information Synthesis
K2-Think orchestrates web searches, document analysis, data extraction, and structured synthesis automatically. Researchers describe 40% time savings on literature reviews and competitive landscape analysis compared to traditional approaches.
Code Generation and Debugging
On LiveCodeBench v6 (880 programming challenges), K2-Think achieves 63.97% accuracy, significantly outperforming similarly-sized peers (GPT-OSS 20B: 42.20%, Qwen3-30B-A3B: 36.9%). The model’s ability to maintain context across multiple related problems and verify intermediate results produces more robust code solutions.
Multi-Step Planning and Compliance
For regulated industries requiring documented decision-making processes, K2-Think’s explicit reasoning traces provide audit trails and compliance documentation. Financial institutions use K2-Think to generate documented analytical reasoning for risk assessments and loan underwriting processes.
Practical Implementation: Getting Results from Day One
First Query Best Practices
Effective prompt structure for optimal K2-Think performance:
- Define the goal explicitly: State the exact problem without ambiguity
- Specify constraints: List all limitations and requirements upfront
- Establish success criteria: Describe how to verify correctness
- Request structured output: Ask for step-by-step reasoning
- Set temperature low: Use 0.1-0.3 for deterministic tasks
Sample High-Performance Prompt:
textGoal: Determine the mathematical probability that a randomly selected 3-digit
number is divisible by both 3 and 7.
Constraints: Must show all work, verify divisibility conditions separately,
provide final probability as reduced fraction.
Success Criteria: Answer matches mathematical definition of probability =
favorable outcomes / total possible outcomes.
Provide solution in these phases:
1. Identify total possible 3-digit numbers
2. Find numbers divisible by 3
3. Find numbers divisible by 7
4. Find numbers divisible by both (LCM)
5. Calculate probability
6. Simplify fraction to lowest terms
Monitoring and Error Handling
pythonimport time
import logging
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def call_k2_with_retry(prompt, max_retries=3, backoff_factor=2):
"""
Call K2-Think with exponential backoff retry logic
"""
for attempt in range(max_retries):
try:
response = requests.post(
'https://api.moonshot.ai/v1/chat/completions',
headers={
'Authorization': f'Bearer {os.getenv("KIMI_API_KEY")}',
'Content-Type': 'application/json'
},
json={
'model': 'kimi-k2-thinking',
'messages': [{'role': 'user', 'content': prompt}],
'temperature': 0.2,
'max_tokens': 4096
},
timeout=60
)
response.raise_for_status()
return response.json()
except requests.exceptions.Timeout:
wait_time = backoff_factor ** attempt
logger.warning(f"Timeout on attempt {attempt + 1}. Retrying in {wait_time}s...")
time.sleep(wait_time)
except requests.exceptions.ConnectionError as e:
wait_time = backoff_factor ** attempt
logger.error(f"Connection error: {e}. Retrying in {wait_time}s...")
time.sleep(wait_time)
except requests.exceptions.RequestException as e:
logger.error(f"Request failed: {e}")
raise
raise Exception(f"Failed after {max_retries} attempts")
Performance Benchmarks and Analytics: By the Numbers
K2-Think’s micro-average accuracy of 67.99% across competitive mathematics benchmarks positions it at the frontier of open-source reasoning—achieved with just 32 billion parameters compared to 120-671 billion for competing models. On the most difficult OMNI-Math-Hard benchmark containing only Olympiad-level problems, K2-Think’s 60.73% pass rate establishes it as the strongest open-source model available for extreme-difficulty mathematical reasoning.
The model’s response length efficiency represents another practical advantage. K2-Think’s “Plan-Before-You-Think” optimization reduces average response lengths by 6-12% compared to the post-training checkpoint, meaning faster inference and lower API costs while simultaneously improving accuracy. On AIME 2024, responses average 20,040 tokens (versus 21,482 for the base checkpoint)—6.72% shorter while achieving 90.83% accuracy compared to the base model’s lower performance.
The 2,000 tokens-per-second inference speed on Cerebras infrastructure represents an order-of-magnitude improvement over typical GPU deployments. For production workloads involving thousands of daily inference requests, this speed differential translates to dramatic cost reduction and improved user experience through reduced latency.
Security, Safety, and Production Readiness
K2-Think underwent comprehensive safety evaluation across four dimensions: High-Risk Content Refusal (83% safety score), Conversational Robustness (89% safety score), Cybersecurity & Data Protection (56% safety score), and Jailbreak Resistance (72% safety score). The model achieves a Safety-4 macro score of 0.750, indicating solid baseline safety with specific strengths in harmful content refusal and consistent multi-turn dialogue safety.
For production deployment, implement these guardrails:
python# Production safety checklist
safety_config = {
"input_validation": {
"max_prompt_length": 100000,
"rejected_keywords": ["harmful", "illegal", "discriminate"],
"rate_limit": "100 requests per minute per API key"
},
"output_monitoring": {
"filter_toxic_content": True,
"validate_factual_claims": True,
"log_all_requests": True
},
"fallback_handling": {
"max_retries": 3,
"timeout_seconds": 120,
"fallback_model": "gpt-3.5-turbo"
}
}
Conclusion and Future Directions
K2-Think represents a fundamental shift in AI economics and accessibility. By proving that a 32-billion parameter model can achieve frontier reasoning performance through sophisticated post-training and inference-time optimization, MBZUAI and G42 have demonstrated that parameter scale alone doesn’t determine capability. The complete transparency of K2-Think—from training code to deployment instructions—enables the global research community to study, reproduce, and build upon these advancements in ways proprietary models never allow.
The practical implications are substantial. Organizations can now implement advanced reasoning capabilities at dramatically lower cost than proprietary alternatives, with full auditability and customization flexibility. As Cerebras’ wafer-scale infrastructure becomes more widely available through cloud providers, K2-Think’s 2,000 tokens-per-second speed advantage will extend to standard enterprise deployments.
For developers beginning their K2-Think journey, start with the free web interface to understand the model’s reasoning process, progress to API integration for production workloads, and eventually explore local deployment for maximum control and customization. The combination of accessibility, transparency, and performance makes K2-Think not just a technical achievement but a democratization moment for advanced AI reasoning.
Source: K2Think.in — India’s AI Reasoning Insight Platform.