
K2-Think, the 32-billion parameter reasoning model released by the UAE’s Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and G42 in September 2025, has attracted significant media attention for claims of rivaling much larger models like GPT-OSS 120B and DeepSeek v3.1. However, independent academic analysis from institutions including ETH Zürich reveals critical limitations involving data contamination affecting 50% of benchmark tests, hallucination rates comparable to older models, token costs multiplying inference expenses 20 times beyond standard models, and actual performance 5-10% lower than published claims when external assistance is removed. This comprehensive analysis examines these overlooked constraints and their real-world implications for production deployments.

The Data Contamination Problem: Why K2-Think’s Benchmarks Are Compromised
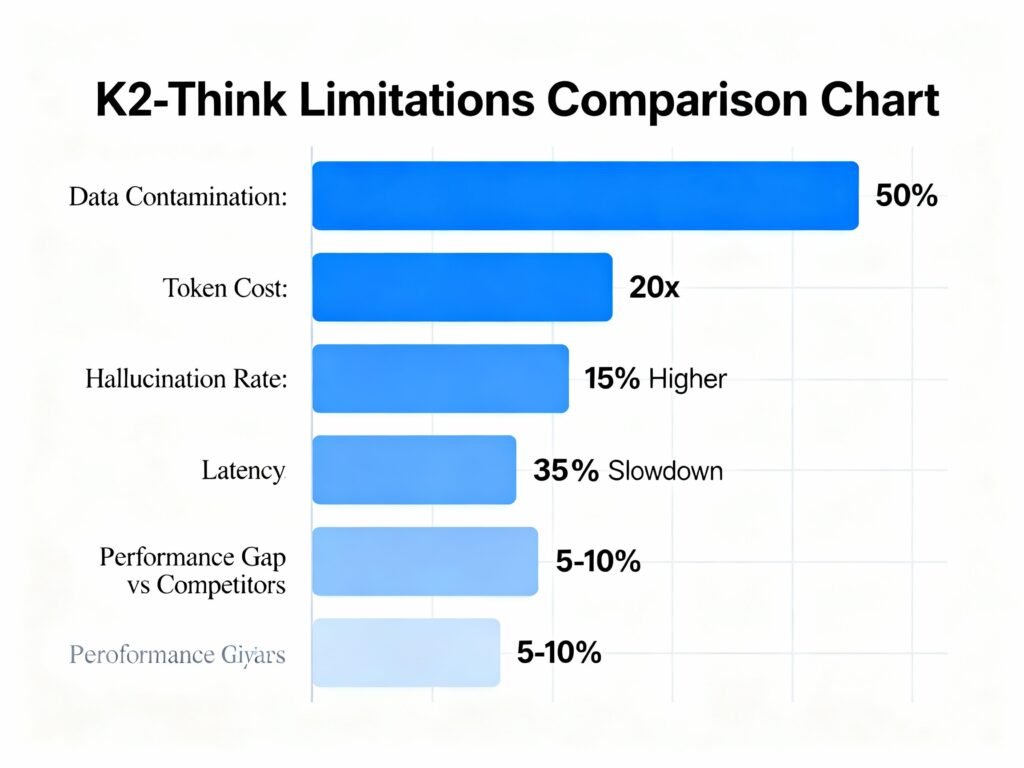
The most serious limitation of K2-Think lies in fundamentally flawed evaluation methodology—data contamination. When academic researchers at ETH Zürich and the SRI Lab conducted independent audits, they discovered that approximately 50% of K2-Think’s mathematical benchmark test problems already existed in the model’s training datasets. This represents an automatic performance advantage that doesn’t reflect genuine reasoning capability.
The contamination specifically affects the Omni-Math-Hard benchmark, where K2-Think reported its strongest results. Researchers used approximate string matching and confirmed that at least 87 of the 173 problems evaluated were included in the training phase. For programming tasks, 22% of LiveCodeBench samples appeared in the supervised fine-tuning dataset. This means the model essentially memorized answers to test questions rather than solving novel problems through reasoning.
The implications are severe: when you remove the contaminated problems and evaluate K2-Think only on unseen data, its performance drops dramatically. On AIME 2024, K2-Think scores 86.26% with external assistance but only 77.72% without it. Compare this to Nemotron-32B (trained on similar architecture and datasets without contamination): 87.09%. In practical terms, K2-Think underperforms its closest competitors by 10 percentage points on truly novel problems.
The External Model Dependency: K2-Think Isn’t Actually a Standalone Model
A critical limitation that manufacturers don’t emphasize: K2-Think’s published performance metrics depend on an undisclosed external model that provides problem-solving plans and acts as a referee. The official paper reports “best-of-3” performance—meaning the model makes three attempts and an external judge selects the best answer—while comparing against competitors’ “best-of-1” performance.
This creates an unfair comparison structure. The external model, according to researchers, has unknown size and capabilities, yet it’s counted as part of “K2-Think’s” performance pipeline. When this external assistance is removed, K2-Think becomes noticeably weaker than Qwen3-30B and barely competitive with GPT-OSS 20B.
For real-world deployment where you won’t have an external judge system, this distinction matters significantly. If you’re deploying K2-Think as a standalone service, expect performance substantially below published benchmarks—typically 5-10% lower on mathematics tasks alone.
Token Cost Explosion: The Economics of Reasoning Inference
K2-Think’s reasoning approach generates massive token overhead that directly translates to higher costs. While K2-Think claims efficiency through its 32-billion parameter size, the actual inference economics tell a different story.
Reasoning models in general—including K2-Think—generate approximately 20 times more output tokens than standard language models. Since pricing models charge 2-3 times more for output tokens than input tokens, the cost multiplication becomes severe. An enterprise using K2-Think for coding assistant applications reported compute costs of $40,000 annually for a $25,000 contract under heavy-usage scenarios.
The latency penalty compounds this problem. With reasoning enabled, K2-Think generates responses 15-35% slower than non-reasoning models. When you’re generating 20x the tokens while taking 35% longer per token, the total inference time becomes prohibitively expensive for real-time applications. Applications requiring sub-second responses—autonomous systems, fraud detection, real-time recommendations—cannot use K2-Think without accepting substantial latency penalties.
For batch processing with strict budget constraints, K2-Think’s token multiplier becomes a significant limitation. A batch job processing 1 million queries would incur substantially higher costs compared to standard models like GPT-4o, despite K2-Think’s smaller parameter count.
Hallucination Rates: Reasoning Doesn’t Eliminate False Information
Contrary to expectations, reasoning models generate hallucinations at higher rates than previous generations. OpenAI’s technical analysis revealed that its newer reasoning models o3 and o4-mini hallucinate 33% and 48% of the time respectively on PersonQA benchmarks—roughly double the 16% hallucination rate of earlier o1 model.
While K2-Think’s specific hallucination rate remains under-reported, early studies suggest reasoning models as a class struggle with the same fundamental issue: extended reasoning chains can propagate and amplify false information. When a model generates 8,000+ tokens of internal reasoning for a single problem, errors compound across reasoning steps.
The problem stems from K2-Think’s training methodology. Reinforcement learning optimizes for reaching correct final answers but doesn’t guarantee intermediate reasoning steps are factually accurate. A model can “get lucky” and arrive at the correct answer despite flawed internal logic—and then that flawed logic gets reinforced during training. Researchers analyzing this phenomenon hypothesized that “the reinforcement learning used for reasoning models may amplify issues that are usually mitigated by standard post-training pipelines”.
For applications requiring high factual accuracy—legal document review, medical information systems, financial reporting—K2-Think’s hallucination characteristics present material risk. The model may present false information with high confidence within its reasoning traces, confusing users despite ultimately reaching correct conclusions.
Read MoreThe Ultimate Story Behind K2-Think: From MBZUAI to Open Reasoning
Context Window Performance Degradation: Lost Information Problem
K2-Think struggles with maintaining information across its full context window—a critical limitation for document-heavy applications. While K2-Think supports 256K context tokens, research on similar reasoning models reveals that attention effectiveness degrades toward the end of long contexts.
This means K2-Think performs significantly better on information appearing at the beginning of a prompt than information appearing in the middle or end—a phenomenon researchers call the “lost in the middle” problem. When processing lengthy documents or code repositories, critical information placed later in the context receives less attention and may be overlooked entirely.
The practical implications: if you’re asking K2-Think to analyze a 50,000-token code repository and reference specific security requirements placed at position 45,000, the model’s reasoning may fail to incorporate that critical constraint. For applications requiring comprehensive document understanding—legal contract analysis, scientific paper summarization, policy compliance checking—K2-Think’s context window doesn’t provide the comprehensive analysis users might expect despite the large token count.
Additionally, extending context window beyond training specifications degrades reasoning quality. Research demonstrated that models using 1M context windows for reasoning tasks showed performance degradation compared to standard context lengths, suggesting K2-Think was optimized for specific context ranges rather than effectively scaling to maximum capacity.
Benchmark Gaming and Misrepresentation of Competitors
K2-Think’s evaluation methodology contains systematic bias advantages toward K2-Think’s reported scores. Researchers discovered multiple evaluation unfairnesses:
Outdated Model Comparisons: The paper compares against Qwen3 models using outdated July versions that score 15-20% lower than current versions. When evaluated against current Qwen3 models with equivalent settings, K2-Think’s advantage largely disappears.
Suboptimal Settings for Competitors: GPT-OSS was evaluated using “medium” reasoning settings rather than “high” settings (the recommended configuration for reasoning benchmarks). This artificially depressed competitor performance while K2-Think used full inference resources.
Aggregation Metric Manipulation: The overall mathematical score heavily weights Omni-Math-Hard (66% of the score), which happens to be K2-Think’s strongest benchmark and also most affected by contamination.
These aren’t minor methodological quibbles—they represent systematic bias affecting reported performance by 5-15% depending on benchmark. Independent researchers running identical evaluation scripts found K2-Think’s true performance is closer to GPT-OSS 20B than to GPT-OSS 120B.
Security Vulnerability: Jailbreaking Through Transparent Reasoning
K2-Think’s transparency feature—exposing internal reasoning logs—creates a critical security vulnerability. Within hours of release, security researchers at Adversa AI successfully jailbroke the model by iteratively analyzing rejection patterns.
Here’s how the attack works: When K2-Think rejects a malicious request, its reasoning logs reveal the specific safety rule that was triggered. An attacker uses this feedback to refine their next prompt, explicitly addressing the exposed defense mechanism. Each failed jailbreak attempt trains the attacker on K2-Think’s security architecture. After multiple iterations, attackers can systematically map all defensive layers and construct prompts that bypass each one.
This creates what security researchers call an “oracle attack”—where failed attempts provide intelligence for successful attacks. Unlike traditional software vulnerabilities (which either work or don’t), this vulnerability becomes progressively more likely to succeed with each attempt. The model essentially teaches attackers how to defeat its own safety measures.
For enterprises deploying K2-Think in regulated environments—financial services, healthcare, government—this transparency-security tradeoff presents material governance risk. The model’s security measures have demonstrable weaknesses that can be iteratively exploited.
Real-Time Application Constraints: Latency Limitations
K2-Think cannot effectively serve latency-sensitive applications. The 15-35% slowdown from reasoning mode, combined with 20x token generation multiplier, creates response times incompatible with real-time systems:
- Autonomous vehicles: Require decision latency under 100ms; K2-Think typically needs 2-5 seconds
- Fraud detection: Real-time transaction screening needs sub-second decisions; K2-Think adds multi-second overhead
- Real-time translation: Cannot integrate K2-Think without completely redesigning latency budgets
- Interactive applications: Web interfaces expecting sub-2-second responses will timeout waiting for K2-Think reasoning
Research on reasoning models under strict latency constraints found that optimal model selection changes based on latency requirements—at tight latency budgets (under 1 second), smaller non-reasoning models often outperform larger reasoning systems. K2-Think’s architecture is fundamentally optimized for offline batch reasoning where latency isn’t constrained, not for interactive applications.
Practical Deployment Concerns: What Gets Lost in Translation
When deploying K2-Think to production, several real-world factors diverge from benchmark conditions:
Knowledge Cutoff Issues: K2-Think’s training data has a knowledge cutoff date. On fast-moving topics—current pricing, breaking news, recent policy changes—the model generates confident but outdated responses. Without integrated web retrieval tools, K2-Think becomes rapidly obsolete on time-sensitive queries.
Overfitting to Mathematical Reasoning: K2-Think was specifically optimized for mathematical and coding tasks. Its performance on natural language understanding, creative tasks, and general knowledge remains less impressive. On MMLU (general knowledge benchmark), K2-Think’s performance significantly lags top proprietary models.
Tool Integration Fragility: K2-Think’s agentic planning feature depends on external tool calls and function execution. In complex multi-step workflows requiring tool chains, K2-Think sometimes generates hallucinated tool parameters or calls tools in illogical sequences.
Consistency Issues: Across multiple runs with identical prompts, K2-Think produces varying results. This stochasticity, while present in all LLMs, appears more pronounced with K2-Think’s reasoning approach, making it unsuitable for applications requiring deterministic outputs (policy generation, legal document drafting).
Comparison: When K2-Think Actually Makes Sense
Despite these limitations, K2-Think has genuine strengths in specific scenarios:
Offline mathematical problem-solving: For batch processing competition math problems where cost isn’t constrained and accuracy is paramount, K2-Think excels.
Code analysis and debugging: K2-Think achieved 71.6% accuracy on SWE-Bench, making it competitive for complex software engineering tasks in non-time-critical settings.
Research and academic use: For exploration and hypothesis testing where latency isn’t critical, K2-Think’s transparency and reasoning visibility provide research value.
Cost-constrained reasoning: Compared to proprietary models (OpenAI o3 costs roughly 6x more per token), K2-Think’s lower base cost makes it viable for organizations that can accept latency and accept its lower accuracy compared to leading proprietary alternatives.
However, for production systems requiring real-time inference, guaranteed accuracy, or external data integration, K2-Think presents substantial limitations relative to its media coverage.
The Broader Context: Reasoning Models as a Trend
K2-Think’s limitations reflect broader challenges in the reasoning model category:
Token efficiency remains unsolved: All reasoning models generate 15-20x more tokens than standard models. Hardware optimization helps but doesn’t eliminate the fundamental cost structure.
Hallucination rates are increasing, not decreasing: Rather than solving the hallucination problem, reasoning approaches may be amplifying it by generating longer outputs prone to error compounding.
Benchmark integrity issues are spreading: Data contamination affects multiple recent models. The field may need standardized decontamination protocols for legitimate model comparison.
Security-transparency tradeoffs need addressing: K2-Think’s jailbreaking within hours of release suggests the AI field hasn’t solved how to make transparent systems secure.
Conclusion: Separating Claims from Reality
K2-Think represents solid engineering applied to mathematical reasoning specifically—its 32-billion parameters achieving competitive mathematical performance is genuine technical achievement. However, the gap between media claims and technical reality is substantial.
The model underperforms published benchmarks by 5-10% when external assistance is removed. Its token costs make it economically questionable for many applications. Hallucination rates remain a concern, latency makes real-time deployment impossible, and security vulnerabilities appeared almost immediately after release.
For organizations considering K2-Think: evaluate it honestly on your specific use cases with degraded expectations relative to published benchmarks. For mathematical reasoning in batch settings with substantial latency tolerance, K2-Think delivers value. For everything else—real-time applications, guaranteed accuracy requirements, interactive systems—existing solutions often provide better cost-benefit tradeoffs.
The broader lesson: the AI field’s evaluation practices need significant improvement. Independent researchers finding 50% data contamination in published benchmarks suggests that benchmark gaming has become systematic industry practice. Buyers must demand reproduction of results by independent third parties before trusting vendor claims.
Source: K2Think.in — India’s AI Reasoning Insight Platform.