
Chain-of-thought (CoT) prompting is one of the most transformative techniques in modern AI, fundamentally changing how large language models approach complex problems. Instead of jumping directly to answers, CoT guides AI systems to think step-by-step, mimicking human reasoning processes. This technique has proven so effective that it’s now reshaping how enterprises deploy AI across healthcare, finance, legal, and technical domains. Research shows that CoT prompting can improve reasoning accuracy by 17.9% to 74% depending on the task and implementation approach, making it essential knowledge for anyone working with AI in 2025.
What Is Chain-of-Thought Prompting?
Chain-of-thought prompting is a simple yet powerful technique that instructs AI models to articulate their reasoning process before reaching a final answer. Rather than asking an AI to solve a problem directly, you ask it to explain each step of its thinking, which fundamentally changes how the model processes information internally.
The beauty of CoT prompting lies in its elegance. You don’t need complex code or special frameworks—just a simple instruction added to your prompt. Phrases like “Let’s think step by step” or “Explain your reasoning before answering” trigger a profound shift in model behavior. When you force a model to show its work, the transformer’s attention mechanisms spend more tokens on each sub-problem, reducing shortcut guesses and surfacing hidden errors.
Consider this practical example: Instead of asking “What is 5 + 6?”, you ask “Let’s think step by step. First, how much is 5? Then, how much is 6? What do we get when we add them together?” This seemingly minor change produces dramatically different internal processing in the model.
The research backing this is compelling. A landmark 2022 study by Google researchers Jason Wei, Xuezhi Wang, and colleagues showed that chain-of-thought prompting improves the ability of large language models to perform complex reasoning, particularly on arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains are striking—prompting a 540-billion parameter model with just eight CoT examples achieved state-of-the-art accuracy on GSM8K (a benchmark of math word problems), surpassing even fine-tuned GPT-3 models with specialized verifiers.
The Problem CoT Solves: Why Models Need to Think Step-by-Step
Before understanding why chain-of-thought is revolutionary, it’s important to understand what problem it solves. Traditional large language models function somewhat like savants—they’re excellent at pattern matching from their training data but struggle with tasks requiring sequential logical reasoning.
LLMs naturally tend to generate outputs in a single pass, jumping from input to answer without explicitly modeling intermediate reasoning steps. This approach works fine for tasks like summarization or creative writing, but for complex multi-step problems, it creates a fundamental weakness: the models make errors not because they can’t understand individual steps, but because they collapse the reasoning process.
In high-complexity tasks—mathematical word problems, logic puzzles, scientific reasoning—this becomes catastrophic. A model might understand how to add numbers, recognize keywords, and identify problem structure, yet fail to integrate these capabilities into a coherent solution path. Traditional prompting offers no way to see which step failed or to encourage the model to be more deliberate.
Enter chain-of-thought prompting. By requiring explicit intermediate steps, CoT transforms the problem-solving landscape. The model must commit to reasoning at each stage, making errors visible and correctability more feasible.
Benchmark Performance: The Numbers Behind CoT’s Success
The performance improvements from chain-of-thought prompting are not marginal—they’re substantial across multiple domains and benchmarks.
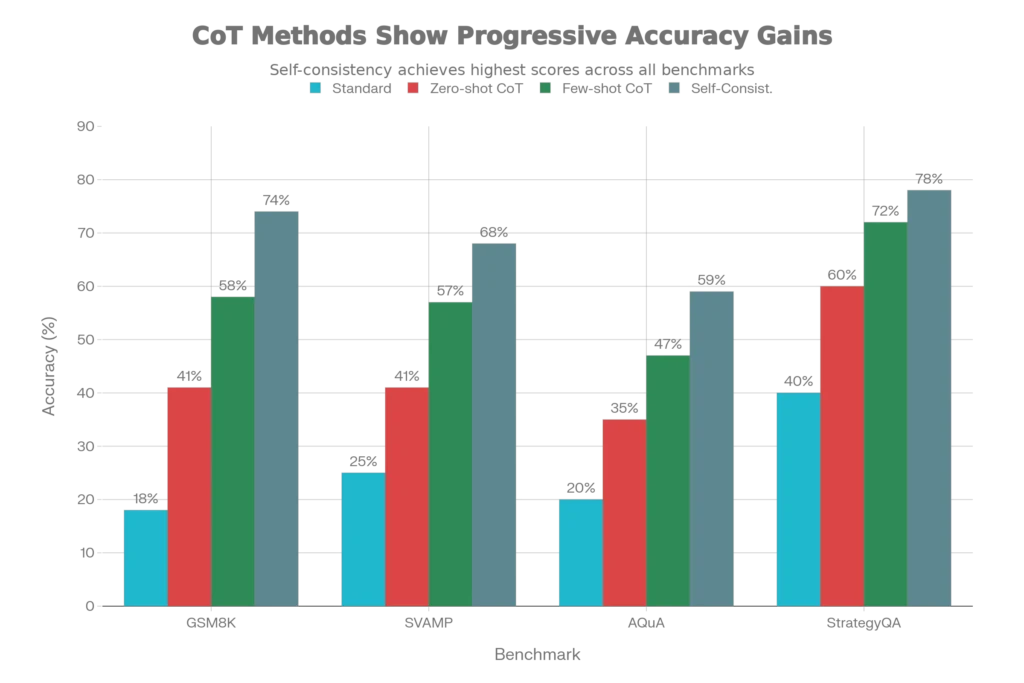
On GSM8K (Grade-School Math Word Problems):
- Standard prompting: 18-20% accuracy
- Few-shot chain-of-thought: 58% accuracy
- Self-consistency CoT: 74% accuracy
On SVAMP (Math word problems with varying complexity):
On AQuA (Aqua Reasoning benchmark):
These aren’t theoretical improvements—they represent the difference between models that can handle real-world problems and models that frequently hallucinate or make logical errors.
The real-world validation came with OpenAI’s o1 model, released in 2024. In a qualifying exam for the International Mathematics Olympiad (IMO), GPT-4o solved only 13% of problems, while the reasoning model scored 83%. On the American Invitational Mathematics Exam (AIME), o1-mini achieved a 74% success rate with single samples, jumping to 83% with consensus among 64 samples, and reaching 93% when re-ranking 1000 samples with a learned scoring function—placing it in the top 500 US students nationally.
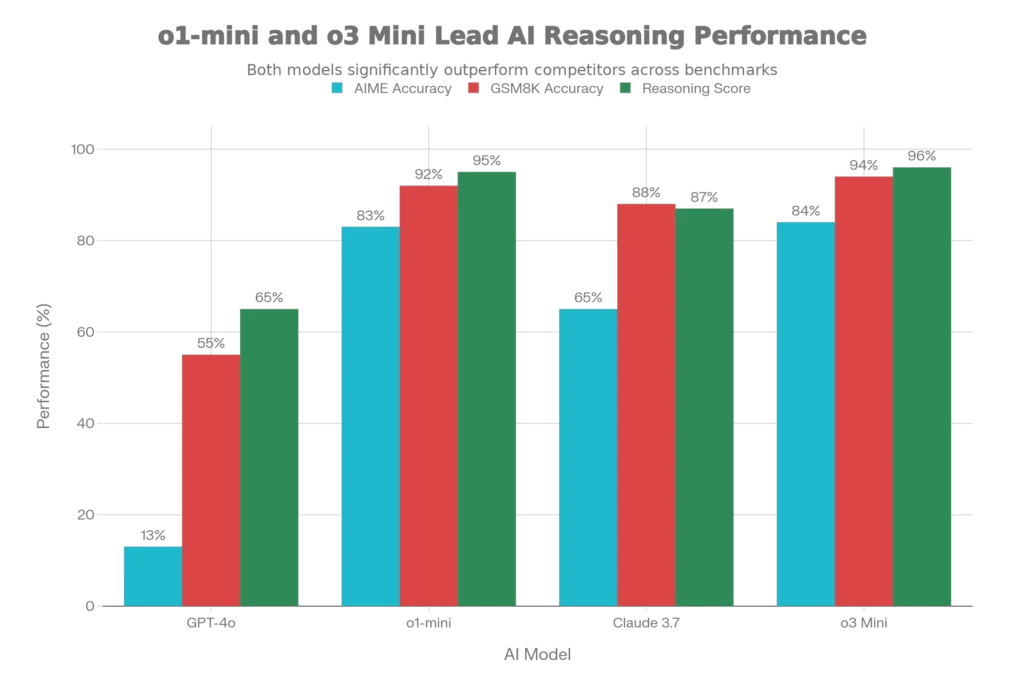
More recent benchmarks from 2025 show even more dramatic advances. O3 Mini achieved an 84% success rate across complex reasoning tasks, while Claude 3.7 demonstrated 87.5% success in pure logical reasoning domains. These represent leaps of 30-40 percentage points over standard prompting approaches.
Types of Chain-of-Thought Prompting: From Zero-Shot to Advanced Techniques
Understanding the different CoT approaches allows you to choose the right technique for your specific use case.
Zero-Shot Chain-of-Thought
Zero-shot CoT is the simplest approach—no examples are provided to the model, just an instruction to think step-by-step. You simply add phrases like “Let’s think step by step” to your prompt without providing demonstrations.
Example:
textProblem: "A store sells apples for $2 each. Sarah buys 5 apples and pays with $20.
How much change does she get?"
Prompt: "Let's think step by step. What is the total cost? How much change from $20?"
Zero-shot CoT works surprisingly well for many tasks, especially with larger models, but it may not consistently produce optimal logical coherence for highly complex problems.
Few-Shot Chain-of-Thought
Few-shot CoT is more powerful because it provides the model with one or more examples showing the desired step-by-step reasoning structure. This teaches the model the exact format and style of reasoning you want.
Example with few-shot prompts:
textExample 1:
Q: "A bakery makes 20 cakes in the morning and 15 in the afternoon. How many total?"
A: "Let's think step by step.
- Morning cakes: 20
- Afternoon cakes: 15
- Total: 20 + 15 = 35 cakes"
Now apply to new problem:
Q: "Sarah had 30 apples. She gave 12 to John and 8 to Maria. How many remain?"
Research shows few-shot CoT consistently outperforms zero-shot across arithmetic, commonsense, and symbolic reasoning tasks.
Self-Consistency Sampling
Self-consistency is an advanced technique that amplifies CoT’s power through statistical voting. Instead of generating a single reasoning path, the model generates multiple different paths to the same answer, and you select the answer that appears most frequently.
This technique is remarkably effective. Research shows self-consistency boosts CoT performance by:
- GSM8K: +17.9% (from 58% to 74%)
- SVAMP: +11.0% improvement
- AQuA: +12.2% improvement
- StrategyQA: +6.4% improvement
The intuition is elegant: complex reasoning problems typically admit multiple valid solution paths, and if a model generates diverse reasoning trajectories independently, the correct answer appears more consistently than incorrect ones.
Automatic Chain-of-Thought (Auto-CoT)
Automatic CoT is a newer approach where the AI itself identifies patterns in similar problems and generates its own exemplary reasoning chains without human input. This scales CoT to domains where manual demonstration creation is expensive.
The process works in stages: First, the model clusters similar questions. Then, for each cluster, it uses zero-shot CoT to generate reasoning. These auto-generated reasoning chains become prompts for similar future questions.
Tree of Thoughts (ToT)
Tree of Thoughts is an advanced evolution that moves beyond linear reasoning chains. Instead of following a single path, ToT maintains multiple reasoning branches simultaneously, allowing the model to explore different approaches and backtrack when a path proves unproductive.
ToT works through four stages:
- Thought Generation: Create multiple potential reasoning steps at each point in the problem
- Thought Evaluation: Assess each branch’s viability using classification (sure/likely/impossible) or comparative voting
- Pruning: Discard unpromising branches to focus computational resources on viable paths
- Search Navigation: Use algorithms like breadth-first or depth-first search to systematically explore the tree
Tree of Thoughts dramatically outperforms linear CoT on complex problems. In Game of 24 puzzles, standard CoT achieved 4% success, while ToT achieved 74%.
How Chain-of-Thought Works: The Mechanism Behind the Magic
Understanding why CoT works requires looking inside the black box of transformer models.
When a language model processes text, it allocates computational attention across tokens. In standard prompting, the model distributes this attention across the entire input-output space, often taking shortcuts for efficiency. For complex problems, this leads to errors because the model hasn’t deeply processed intermediate logic.
CoT forces deeper processing through several mechanisms:
Increased Token Allocation: By explicitly requiring reasoning steps, CoT instructions cause transformer attention heads to spend more tokens on each sub-problem. Rather than rushing to an answer, the model carefully processes each intermediate step.
Explicit Representation of Logic: Intermediate steps create explicit, human-readable representations of logical connections. This “showing of work” forces the model to maintain coherent reasoning rather than making probabilistic shortcuts.
Enhanced Feature Extraction: The structured reasoning reveals features of the problem that single-pass processing might miss. Multi-step reasoning activates different neural pathways, accessing diverse patterns learned during training.
Error Correction Opportunities: Visible intermediate steps create checkpoints where errors become apparent. If step 3 contradicts step 1, both the model and human observers can identify and correct the inconsistency.
Large-scale models (100B+ parameters) benefit most from CoT because they have sufficient capacity to flexibly shift between reasoning modes. Smaller models (7B-13B parameters) sometimes show less benefit or even degradation because their attention mechanisms aren’t sophisticated enough to fully leverage the extra tokens.
Why CoT Fails and When It Creates Problems
While chain-of-thought prompting is powerful, it’s not a universal solution. Recent research reveals important limitations and trade-offs.
The Hallucination Paradox
A 2025 study from Apple’s Machine Learning Research group reveals a counterintuitive finding: while CoT prompting improves accuracy, it simultaneously obscures critical hallucination detection signals.
The research evaluated multiple hallucination detection methods and found that CoT prompting led to:
- More concentrated hallucination score distributions
- Reduced classification accuracy in detecting false claims
- Poorer calibration between model confidence and actual correctness
This creates a dangerous scenario: The model produces text that appears well-reasoned through explicit step-by-step thinking, but the additional reasoning can actually mask false assumptions or fabricated information. Self-evaluation methods particularly suffer, with some advanced hallucination detectors losing their advantage over simple perplexity baselines when CoT is applied.
The Abstention Problem
Another critical finding from 2025 research: Reasoning-optimized models like DeepSeek-R1 and related systems actually perform worse at abstention—knowing when to say “I don’t know”—compared to standard models.
The study, which evaluated 20 frontier models on AbstentionBench, found that:
- Standard models abstain correctly 40-50% of the time on uncertain questions
- Reasoning models degrade by an average of 24% on abstention
- DeepSeek-R1 (Distill Llama 70B) shows a 24% drop compared to its non-reasoning baseline
- Models hallucinate missing context rather than admitting uncertainty
This is especially problematic in domains like healthcare and finance where knowing the limits of a model’s knowledge is critical.
The Illusion of Reasoning
Apple’s 2025 research on “The Illusion of Thinking” identifies a fundamental limitation: reasoning models improve performance up to a complexity threshold, then completely collapse.
The research found three performance regimes:
- Low-complexity tasks: Standard models surprisingly outperform reasoning models (potentially due to overhead)
- Medium-complexity tasks: Reasoning models show advantage and extended thinking provides value
- High-complexity tasks: Both reasoning and standard models experience complete accuracy collapse
Additionally, models exhibit a counterintuitive “scaling limit” where reasoning effort increases with problem complexity up to a point, then declines despite having adequate token budget.
Practical Implementation: Real-World Applications Across Industries
The theoretical benefits of CoT translate into measurable business value when properly implemented.
Healthcare and Medical Diagnosis
Medical institutions use CoT to enhance diagnostic decision support. Rather than giving a single diagnosis, AI systems reason through symptoms step-by-step:
“The patient presents with fever (102°F), body aches, and fatigue lasting 3 days.
- Step 1: Fever + aches + fatigue suggests systemic infection
- Step 2: 3-day duration rules out acute injury or trauma
- Step 3: No respiratory symptoms, so respiratory infection less likely
- Step 4: Seasonal timing and community cases of flu suggest viral infection
- Conclusion: Likely influenza, recommend antigen test”
This reasoning chain allows doctors to verify the AI’s logic, catch potential errors in symptom interpretation, and maintain appropriate oversight.
Financial Risk Analysis
Finance teams use CoT for credit evaluation and fraud detection:
“Credit risk assessment for $50,000 loan request:
- Step 1: Credit score 680 indicates higher risk profile
- Step 2: 3-year employment history suggests moderate stability
- Step 3: Debt-to-income ratio 35% is within acceptable range
- Step 4: Recent missed payment increases risk
- Step 5: Overall: Approve with 7.5% interest and income verification requirement”
This structured approach is crucial in regulated financial environments where decisions must be justified and defensible.
Legal and Compliance Analysis
Legal firms apply CoT to contract analysis and regulatory compliance:
“Does this employment contract comply with California labor law?
- Step 1: Classification: Employee vs. Contractor determination
- Step 2: Wage and hour: Minimum wage and overtime provisions adequate
- Step 3: Termination: At-will employment properly stated
- Step 4: Non-compete: Restricts future employment, may violate CA Business & Professions Code 16600
- Step 5: Conclusion: Contract requires amendment to non-compete clause”
The step-by-step reasoning creates an audit trail and helps legal teams identify problematic clauses before agreements are executed.
Enterprise Business Impact and ROI
Organizations implementing systematic prompt engineering (of which CoT is central) report significant financial returns:
- Operational Efficiency: 15-20% higher first-contact resolution in customer support
- Processing Speed: 20-30% faster handling times for AI-assisted workflows
- Cost Reduction: Companies report spending nearly half as much time on repetitive analytical work
- Time Savings: McKinsey research documents companies cutting analysis time by up to 50%
- Enterprise Scale: Average savings of $2.3 million annually per 100-person department for organizations using advanced prompt strategies
For manufacturing, predictive maintenance using reasoning-enhanced AI achieved 823% ROI (savings: $24M over 18 months, investment: $2.6M).
A logistics company implementing refined prompt engineering cut manual query handling by 40% simply through improved template design.
Advanced Techniques and 2025 Innovations
The field of reasoning-enhanced prompting has evolved rapidly, with several emerging techniques pushing beyond basic CoT.
Least-to-Most Prompting
This technique breaks complex problems into simpler constituent parts that are solved sequentially, with solutions to simpler parts informing solutions to more complex parts.
Performance advantage: 99.7% accuracy on length generalization tasks vs. 16.2% for standard CoT.
Layered Chain-of-Thought (2025)
Emerging technique breaking reasoning into multiple passes with opportunities to review and adjust between layers. Particularly valuable in healthcare and finance where multi-stage review is critical.
Trace-of-Thought
Designed specifically for smaller models (~7B parameters), this approach creates subproblems to improve arithmetic reasoning on resource-constrained hardware.
ReAct Prompting
Combines reasoning traces with real-time action execution, creating a “think-act-observe” cycle. Models can reason about problems while accessing live information through API calls, eliminating hallucination from outdated training data.
Self-Evaluation and Meta-Reasoning
Advanced frameworks like MR-GSM8K require models to not only solve problems but to critique their own answers, identify logical errors, and explain mistakes. This creates a second layer of reasoning quality control.
Optimization Tips: Making CoT Work Better
Based on 2025 research and production implementations, several evidence-based practices improve CoT effectiveness:
1. Match Complexity to Model Size
CoT works best with models 100B+ parameters. Smaller models (7B-13B) may show diminished returns unless specifically fine-tuned. O3 Mini (with optimized reasoning) outperforms much larger non-reasoning models.
2. Use Few-Shot Over Zero-Shot When Possible
Few-shot CoT consistently outperforms zero-shot because it demonstrates your preferred reasoning style. One or two well-chosen examples provide substantial accuracy gains.
3. Implement Self-Consistency for Critical Decisions
For high-stakes applications, generate 5-10 diverse reasoning paths and use majority voting. The 17.9% accuracy improvement on GSM8K demonstrates its power.
4. Add Explicit Verification Steps
Include instructions for models to verify intermediate conclusions: “Check that Step 2 follows logically from Step 1.” This reduces error propagation.
5. Control Temperature Carefully
Higher temperature (0.7-0.9) generates more diverse reasoning paths for self-consistency. Lower temperature (0.2-0.4) provides more reliable single-path reasoning.
6. Be Specific About Output Format
Rather than “explain your reasoning,” use “provide exactly 5 numbered steps of reasoning before your final answer.” Specificity reduces token usage and improves consistency.
7. Monitor for Hallucination in Reasoning
Don’t assume detailed reasoning chains are accurate. Implement fact-checking systems, especially in healthcare, finance, and legal domains. Apple’s 2025 research shows CoT can mask hallucinations.
The Future of Chain-of-Thought: Where AI Reasoning is Heading
The trajectory of AI reasoning points toward several important developments for 2025 and beyond:
Multimodal Reasoning will combine text, visual, and potentially audio information. GSM8K-V (visual versions of math problems) shows that even advanced models achieve only 46.93% accuracy on visual reasoning compared to near-saturation on text.
Culturally-Adaptive Reasoning is emerging as important. Research shows LLMs exhibit significant accuracy drops on culturally re-templated problems (different names, currencies, scenarios for various regions), and explicit CoT can partially mitigate these gaps.
Formal Verification Integration combines chain-of-thought reasoning with formal theorem proving, ensuring reasoning meets mathematical rigor standards. Current systems show 16.46% success rates on formal mathematics, indicating substantial development potential.
Autonomous Tool Use will embed reasoning with API access, allowing models to autonomously select and execute appropriate tools (calculators, databases, search engines) while maintaining coherent reasoning chains.
Production-Grade Observability is becoming critical. Organizations are implementing monitoring systems that track prompt performance in production, identify reasoning regressions, and optimize prompts based on real-world performance data.
Addressing Common Misconceptions About Chain-of-Thought
Several myths about CoT persist in the practitioner community:
Myth 1: “CoT works equally well on all tasks”
Reality: CoT is most effective for reasoning-intensive tasks (math, logic, multi-step decisions). For simple classification, sentiment analysis, or summarization, it provides minimal benefit and can add unnecessary overhead.
Myth 2: “Longer reasoning chains are always better”
Reality: Research shows diminishing and sometimes negative returns. Models can over-reason on simple problems, introducing errors and wasting computational resources. Quality matters more than quantity.
Myth 3: “CoT eliminates hallucination”
Reality: 2025 research demonstrates that while CoT reduces hallucination frequency, it simultaneously obscures hallucination detection mechanisms, potentially making false information appear more trustworthy.
Myth 4: “More reasoning budget always improves accuracy”
Reality: Frontier models show complete collapse on high-complexity tasks regardless of reasoning budget. Additional thinking effort hits a complexity wall, then performance degrades.
Myth 5: “Enterprise should switch entirely to reasoning models”
Reality: Standard models outperform reasoning models on simple tasks and show better abstention (knowing when they don’t know). The ideal approach combines both intelligently.
Implementation Checklist for Organizations
For teams implementing chain-of-thought across production systems:
Planning Phase:
- ✓ Define specific use cases where reasoning provides value (complex problem-solving, explanation requirements)
- ✓ Benchmark current model performance to establish baseline
- ✓ Identify downstream accuracy requirements and compliance constraints
Development Phase:
- ✓ Start with few-shot CoT using 1-3 representative examples
- ✓ Test zero-shot CoT to reduce example engineering burden
- ✓ Implement self-consistency sampling (5-10 paths) for critical decisions
- ✓ Add verification steps that check reasoning coherence
- ✓ Establish output format standards to reduce variability
Validation Phase:
- ✓ Test hallucination rates alongside accuracy improvements
- ✓ Evaluate abstention performance on uncertain inputs
- ✓ Conduct adversarial testing with edge cases
- ✓ Have subject matter experts review reasoning chains for domain accuracy
- ✓ Benchmark cost per query to ensure acceptable economics
Production Phase:
- ✓ Implement monitoring to track prompt performance over time
- ✓ Set up alerts for accuracy degradation or hallucination increases
- ✓ Create feedback loops where incorrect reasoning is logged for retraining
- ✓ Document reasoning chains for audit and compliance trails
- ✓ Establish version control for prompt templates
The Bottom Line: Why CoT Matters in 2025
Chain-of-thought prompting represents a fundamental shift in how we interact with AI systems. Rather than treating models as black boxes that magically produce answers, CoT makes reasoning explicit, auditable, and improvable.
The performance gains are real and measurable: 73-74% accuracy on mathematical reasoning with self-consistency CoT versus 18% with standard prompting. The business impact is tangible: organizations report 40% cost reductions, 30% faster decision-making, and measurable improvements in customer satisfaction.
But CoT is not a panacea. It doesn’t work equally on all tasks, it can mask hallucinations, and it hits complexity ceilings. The future belongs to organizations that understand both its power and its limitations—that implement it strategically rather than universally, and that combine CoT with other techniques like self-consistency, verification, and proper oversight.
As AI systems take on increasingly consequential roles in healthcare, finance, and law, the ability to see and verify reasoning becomes not just an optimization but an ethical necessity. Chain-of-thought prompting is a critical step toward that transparency and trustworthiness.
Read More:TinyLLM: Best AI Models for Android Phones
Source: K2Think.in — India’s AI Reasoning Insight Platform.