
Imagine watching a precious family video or an important archival recording, only to realize it’s stuck in 480p quality—pixelated, blurry, and unusable for modern displays. For years, this problem seemed unsolvable without costly re-shooting or professional restoration. Today, AI video upscalers have revolutionized this landscape, offering a practical solution that transforms low-resolution footage into stunning 4K clarity. This transformation isn’t just stretching pixels anymore; it’s intelligent reconstruction powered by deep learning algorithms trained on millions of high-resolution images. Whether you’re a content creator, filmmaker, or someone preserving precious memories, understanding how AI video upscalers work and when to use them can save you thousands of dollars while delivering professional-grade results from home.
Understanding AI Video Upscaling: The Technology Behind the Transformation
What Exactly is AI Video Upscaling?
AI video upscaling represents a fundamental shift in how we enhance video resolution. Unlike traditional upscaling methods that simply stretch existing pixels using mathematical formulas like bicubic or Lanczos interpolation, AI-powered upscalers use deep learning neural networks trained on vast datasets of paired low-resolution and high-resolution images. When you feed a 480p video into an AI upscaler, the system doesn’t just guess how to fill in missing details—it analyzes thousands of patterns it has learned from high-quality footage to intelligently reconstruct what should be there.
The core principle behind this technology involves teaching machines to recognize what real-world objects, textures, and faces actually look like at higher resolutions. The neural network learns to map low-resolution input patterns directly to high-resolution output patterns, capturing non-linear relationships that traditional mathematical approaches cannot handle. This means the AI can understand context—it knows that a blurry face should become sharp and detailed, that fabric textures should look realistic, and that edges should be crisp without introducing artificial halos.
The magic of AI upscaling lies in its ability to reconstruct missing information. When you downscale a 4K video to 480p, you lose approximately 93.75% of the pixel information. Traditional upscaling cannot recover this lost data; it can only make educated guesses based on neighboring pixels. AI upscalers, trained on millions of examples, can reconstruct realistic details that match what would naturally exist in high-resolution footage.
How Deep Learning Models Process Video Frames
AI video upscaling typically follows a four-stage process that distinguishes it from conventional methods. First, the AI performs an analysis phase, examining your low-resolution video and identifying objects, textures, edges, and motion patterns. During this stage, the neural network activates different regions of its learned knowledge based on what it sees—a person’s face triggers specific feature recognition, while landscapes activate different pattern-matching pathways.
The second stage involves pattern recognition. Based on its training, the AI recognizes what things should look like. It understands that human faces have specific proportions and textures, that tree leaves have particular patterns, and that fabric should have realistic weave structures. This knowledge comes from being trained on datasets containing thousands of examples showing how things appear at different resolutions.
The third stage is detail generation, where the algorithm generates new pixels that fit naturally with the surrounding content. This is where the real intelligence shows through. Rather than inventing random details, the AI creates pixels that maintain consistency with the original content while matching realistic patterns learned during training. For instance, if it identifies a person’s skin in the original footage, it will generate skin textures consistent with real human skin, not artificial patterns.
Finally, the refinement stage removes artifacts, reduces noise, and ensures smooth motion between frames. This temporal consistency is particularly important for video, as viewers notice flickering or jumping between frames far more easily than they notice slight static artifacts.
AI Video Upscaling Process: From 480p Input to 4K Output Through Neural Network Processing
The Neural Network Architectures Powering Modern Upscalers
SRCNN: The Pioneering Deep Learning Approach
The Super-Resolution Convolutional Neural Network (SRCNN) represents an early breakthrough in applying deep learning to upscaling. Introduced by Dong et al., SRCNN uses a three-layer convolutional neural network architecture that was revolutionary for its time. The network performs three main operations: feature extraction from the low-resolution image, non-linear mapping of these features to high-resolution feature space, and finally, reconstruction of the high-resolution image.
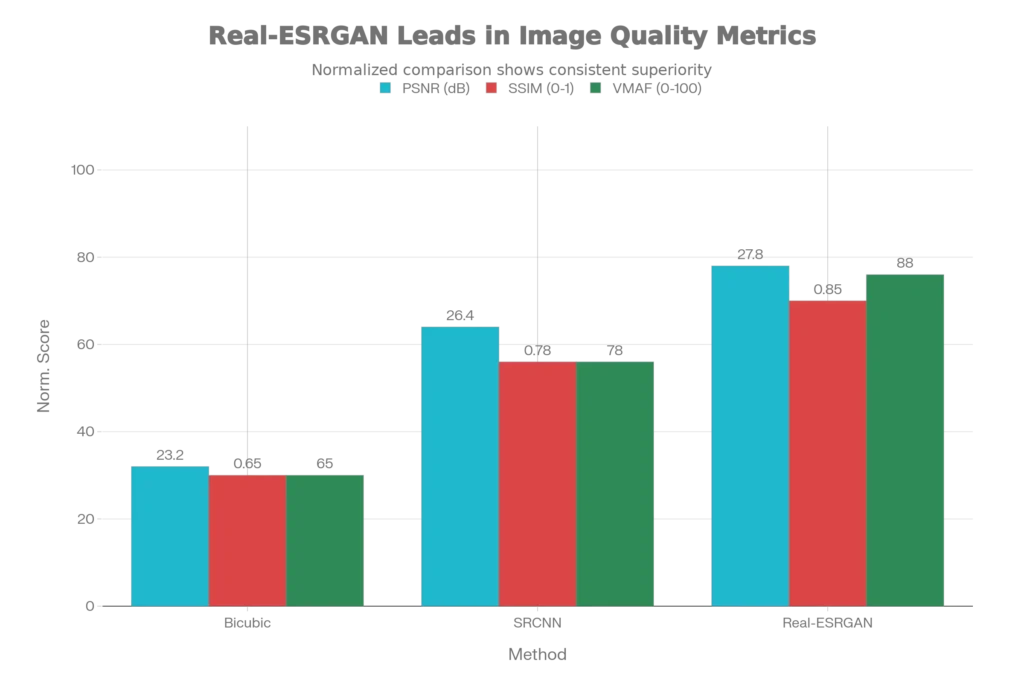
Research published in medical imaging demonstrated that SRCNN significantly outperformed traditional linear interpolation methods. In studies on chest CT images, SRCNN achieved a test PSNR of 26.442 dB compared to a baseline bicubic upsampling PSNR of 23.226 dB—a measurable and visually apparent quality improvement. For a 4x magnification (similar to upscaling from 480p to 4K), SRCNN preserved high-frequency components that traditional methods lost, resulting in images that closely resembled the original without obvious artifacts.
The key innovation of SRCNN was proving that deep neural networks could learn the mapping between low-resolution and high-resolution spaces more effectively than mathematical formulas. However, SRCNN required pre-upscaling of input images using bicubic interpolation, which added computational overhead.
ESPCN: Efficient Sub-Pixel Convolution for Real-Time Performance
The Efficient Sub-Pixel Convolutional Neural Network (ESPCN) improved upon SRCNN by introducing a more efficient architecture that could handle upscaling in the low-resolution space. Rather than requiring pre-upscaling using traditional interpolation, ESPCN performs most of its processing on the original low-resolution image and handles the final upscaling through a novel sub-pixel convolution layer.
This architectural innovation offered significant practical advantages. By performing feature extraction and processing in the low-resolution space before upscaling, ESPCN reduced computational complexity and memory requirements compared to SRCNN. The sub-pixel convolution layer learned an efficient upscaling operation using fractional strides, activating different parts of convolution filters depending on pixel locations. This approach saved substantial computational costs while maintaining or improving quality, making it practical for real-time applications.
ESPCN incorporates the SSIM (Structural Similarity Index) loss function in addition to traditional fidelity metrics. This focus on perceptual quality rather than just mathematical accuracy makes ESPCN particularly effective for applications where human visual perception matters more than pixel-perfect reconstruction.
Real-ESRGAN: Handling Real-World Degradation
Modern upscaling has evolved significantly with Real-ESRGAN, developed by Wang et al. in 2021. Unlike earlier methods that assumed simple bicubic degradation during training, Real-ESRGAN addresses the real-world problem that actual low-resolution footage contains complex degradation including blur, noise, JPEG compression artifacts, and resizing artifacts.
Real-ESRGAN uses a two-stage training approach. The first stage trains on synthetically degraded images, while the second stage fine-tunes on real-world low-quality images using weak supervision. This hybrid approach makes Real-ESRGAN exceptionally effective on diverse, severely degraded inputs—the kind of old footage, compressed videos, and streaming content that real users actually work with.
The architecture employs Residual-in-Residual Dense Blocks (RRDB) for improved feature learning and employs a U-Net discriminator for enhanced adversarial training. Research comparing methods on quantitative evaluation metrics shows Real-ESRGAN achieving superior PSNR and SSIM scores compared to both ESRGAN and traditional methods.
Generative Adversarial Networks: The Competitive Learning Approach
Generative Adversarial Networks (GANs) have become central to state-of-the-art video upscaling. In GAN-based super-resolution, two neural networks compete against each other—a generator network creates high-resolution images, while a discriminator network tries to distinguish between generated and real high-resolution images.
This adversarial process drives continuous improvement. The generator learns not just to produce high PSNR scores (which can result in blurry outputs) but to create images that fool an increasingly sophisticated discriminator. The discriminator, trained on real high-resolution images, teaches the generator what realistic high-frequency details look like. This results in upscaled images with sharp textures, detailed edges, and perceptually pleasing results that match what humans expect from high-resolution footage.
GANs introduce perceptual loss functions alongside traditional fidelity metrics. These perceptual losses use pre-trained networks to measure whether the generated image “feels” like a real high-resolution image, even if it doesn’t perfectly match the original pixel-by-pixel. This approach aligns upscaling results with human visual perception rather than mathematical accuracy alone.
Measuring Video Quality: PSNR, SSIM, and VMAF Explained
PSNR: The Traditional Metric with Limitations
Peak Signal-to-Noise Ratio (PSNR) measures how much a reconstructed video deviates from the original by calculating the ratio of peak signal power to noise in decibels (dB). A higher PSNR value generally indicates better quality, with typical values for lossy video compression ranging between 30 and 50 dB for 8-bit video.
While PSNR is simple to calculate and has been used for decades, it has a critical limitation: it doesn’t always correlate with human perception. Two videos can have the same PSNR score but look significantly different to human viewers. PSNR treats all pixel errors equally, so a video with slight blurring across all frames might score the same as a video with severe artifacts in isolated frames. Additionally, PSNR can give misleadingly high scores for videos that suffer from problematic distortions like color banding, motion artifacts, or temporal flickering—issues that significantly impact real-world viewing quality.
SSIM: Structural Similarity for Perceptual Alignment
Structural Similarity Index (SSIM) improves upon PSNR by considering structural information, luminance, and contrast patterns that align more closely with human visual perception. Rather than just comparing pixel differences, SSIM evaluates whether the processed video maintains the same structure and appearance as the original.
SSIM is particularly effective at detecting content-dependent distortions, measuring the impact of noise, and capturing blurring artifacts. When using SSIM for optimization during encoding, tools can allocate bitrate more intelligently, sending more data to areas with important detail and less to smooth, featureless regions. SSIM ranges from 0 to 1, with 1 indicating perfect structural similarity. Research shows SSIM scores above 0.85 typically indicate very good perceptual quality.
VMAF: The Netflix-Developed Perception-Based Standard
Video Multimethod Assessment Fusion (VMAF) represents the current gold standard in video quality assessment. Developed collaboratively by Netflix, the University of Southern California, the University of Nantes, and the University of Texas at Austin, VMAF uses machine learning to predict human-perceived video quality.
VMAF goes beyond pixel-based metrics by incorporating machine learning models trained on extensive subjective human viewing tests. Rather than assuming all distortions affect perception equally, VMAF learns which types of distortions matter most to viewers and weights them accordingly. It considers motion, texture details, edge artifacts, and other visual elements, producing scores that correlate far more strongly with actual human perception than PSNR or even SSIM.
VMAF scores range from 0 to 100, with higher scores indicating better perceived quality. Most streaming services now use VMAF as their primary metric for quality assurance. Research shows that combining VMAF with PSNR and SSIM provides the most comprehensive evaluation of both mathematical accuracy and human visual experience.
Leading AI Video Upscaling Tools and Their Capabilities
Professional-Grade Solutions: Topaz Video AI
Topaz Video AI stands as the professional industry standard for video enhancement, offering specialized AI models designed for different content types. The software includes multiple upscaling models: Proteus for general upscaling of medium-quality footage, Gaia for high-quality source material, Artemis for all-quality videos, and Theia for additional sharpening and detail enhancement.
Performance testing shows Topaz’s Artemis model delivering superior results across objective quality metrics. The software also includes specialized models like Iris for face restoration, enabling targeted enhancement of facial details while preserving overall video quality. For users requiring precise control, Topaz offers extensive customization options, though this comes at the cost of a steeper learning curve compared to simpler alternatives.
Topaz requires a powerful dedicated GPU (NVIDIA RTX recommended) for optimal speed. Processing times depend heavily on video length, resolution, and the chosen model, but typically range from several minutes for short clips to hours for feature-length films. The annual subscription model ($299/year) positions it as a premium professional solution.
Accessible and User-Friendly Options: AVCLabs and HitPaw
AVCLabs Video Enhancer AI prioritizes ease of use with fewer but general-purpose AI models and an intuitive interface. It processes videos faster than Topaz and requires less powerful hardware, making it accessible for creators without high-end equipment. AVCLabs includes a dedicated neural network for colorizing black-and-white footage—a feature Topaz doesn’t include.
Direct performance comparisons show AVCLabs producing good results for basic upscaling but with less detail preservation than Topaz, particularly in noise reduction. AVCLabs processes video at approximately 1 fps for denoising compared to faster speeds on professional tools. The lifetime purchase option ($299.90) makes it cost-effective for users not needing professional-grade customization.
HitPaw brings AI upscaling to beginners with automatic settings and a clean interface. It focuses on simplicity, enabling users to upscale videos to 4K in just a few clicks while maintaining natural detail and motion accuracy. HitPaw offers multiple AI models including general upscaling, denoising, face refinement, and color enhancement options.
Cloud-Based Solutions: Pixop and SimaUpscale
Pixop differentiates itself through cloud-based processing, eliminating the need for powerful local hardware. Users upload videos to Pixop’s servers where high-performance processing handles the upscaling, ideal for professionals and studios handling large volumes. The cloud approach enables scalable processing, bulk uploads, and parallel rendering—essential for agencies restoring multiple assets simultaneously.
SimaUpscale leads the real-time upscaling space, verified with industry standard quality metrics and delivering ultra-high quality upscaling in real time. The technology boosts resolution instantly from 2× to 4× with seamless quality preservation, upscaling to 4K. For creators just getting started, SimaUpscale’s free trial provides immediate access to real-time upscaling without hardware investments or complex setup procedures.
The Science of Resolution Enhancement: From 480p to 4K
Understanding Resolution Multiplication Factors
Upscaling from 480p to 4K represents a 4× linear upscaling factor (since 480p × 4 = 1920p, approximately 4K). However, the pixel count increases by a factor of 16—480p contains approximately 259,200 pixels per frame, while 4K contains 8,294,400 pixels. This means the AI must reconstruct approximately 97% of the pixels in the final output, with only 6.25% of pixels directly derived from the original source.
Most modern upscalers handle this through multiple scaling passes. Rather than attempting a single 4× upscaling operation—which compounds errors—sophisticated tools may perform two 2× upscalings sequentially or use adaptive scaling that adjusts its approach based on content. This staged approach produces better results because each step has less work to do and fewer details to hallucinate.
Research indicates that upscaling factors beyond 4× start producing increasingly interpretive rather than reconstructive results. A 480p source upscaled 8× to 8K is pushing the boundaries of what any method can realistically achieve, though modern AI tools handle this far better than traditional interpolation would.
Temporal Consistency: The Video-Specific Challenge
Video upscaling presents unique challenges that image upscaling doesn’t face. Between consecutive frames, the content shifts due to camera movement, object motion, and scene changes. If upscaling algorithms process each frame independently without understanding motion, the result is visible flickering and temporal inconsistency—motion appears jittery, and stationary objects flicker unnaturally.
Advanced video upscaling models address this through temporal consistency mechanisms. Recurrent Neural Networks (RNNs) with memory-preserving techniques like LSTM (Long Short-Term Memory) layers model temporal dynamics across frames. These networks learn to maintain consistency by considering multiple frames together, understanding that a facial feature should look the same (or change predictably) from one frame to the next.
Recent advances like Upscale-A-Video employ local-global temporal strategies. Locally, temporal layers within the neural network maintain consistency within short video segments, preventing frame-to-frame flickering. Globally, flow-guided recurrent latent propagation modules enhance consistency across entire videos, managing complex camera movements and scene changes. Temporal warping error measurements quantify consistency—lower warping errors indicate better temporal coherence.
Motion Artifact Prevention and Detail Recovery
Traditional upscaling often produces motion artifacts—areas where motion blur introduces strange patterns, edges become jagged, or moving objects leave trails. These artifacts result from the upscaler’s inability to understand motion directionality.
Modern AI upscalers tackle this through motion-aware processing. Topaz Video AI includes frame interpolation features that can add intermediate frames between existing frames, smoothing motion. Other approaches like motion compensation analyze optical flow (the apparent motion of pixels between frames) to understand how content moves, then apply upscaling that respects this motion direction.
Specialized models like Topaz’s Chronos or RIFE (Real-Time Intermediate Flow Estimation) can generate additional frames for slow-motion effects, essential when upscaling archived footage that might have variable frame rates or motion blur. These models understand that motion should remain smooth and coherent, not introducing artifacts that didn’t exist in the original footage.
Real-World Performance: Bitrate Reduction and Practical Benefits
The Economics of AI-Enhanced Video Delivery
AI-based super-resolution techniques provide significant economic advantages for video streaming. Experiments demonstrate that AI-powered upscaling can achieve bitrate savings of up to 29% compared to traditional upscaling methods while maintaining perceived quality. This means streaming services could deliver what appears to be higher-quality video while using substantially less bandwidth—directly reducing CDN costs and improving profitability.
The mechanism is straightforward: instead of encoding video at full 4K resolution and bitrate, streaming services can encode at 1080p or 720p using modern efficient codecs, then upscale in real-time on the viewer’s device during playback. The upscaling happens at the edge (on the user’s GPU), not on expensive cloud servers, reducing infrastructure costs while improving delivery speeds.
This approach addresses a critical challenge in streaming services: delivering optimal quality across diverse viewer hardware and network conditions. A viewer with limited bandwidth sees a sharp 1080p stream that their device intelligently upscales to their display resolution, while viewers with fast connections can receive full-resolution streams.
Bandwidth Reduction Through Preprocessing
AI-enhanced preprocessing engines can reduce video bandwidth requirements by 22% or more while boosting perceptual quality. These preprocessing stages analyze video before encoding, applying intelligent noise reduction, deblurring, and detail enhancement that eliminates waste in the encoding process. When the encoder then compresses this enhanced video, it achieves better results at lower bitrates.
Market Growth and Industry Adoption Rates
The global AI video upscaling software market demonstrates explosive growth. The market was valued at $3.3 billion in 2025 and is projected to grow to $9.5 billion by 2033, representing a compound annual growth rate (CAGR) of 22.10%. This explosive growth reflects increasing recognition of video quality as critical to viewer retention and brand perception.
Driving this adoption are several factors: the massive installed base of legacy low-resolution content that streaming services own, the rising expectations for 4K and 8K content across all platforms, and the economic benefits of upscaling over re-shooting or purchasing expensive new footage. Gaming, streaming services, social media, and content editing represent the fastest-growing application segments.
Practical Applications: When and How to Use AI Video Upscalers
Documentary and Historical Footage Restoration
Archival footage often exists in low-resolution formats that were acceptable for older displays but look terrible on modern 4K screens. Historical documentaries, news footage from decades past, and personal videos from the era of consumer DV cameras all benefit dramatically from AI upscaling.
Documentary filmmakers can restore frame rates, remove compression artifacts, and present historical footage at resolutions suitable for modern theatrical release or streaming platforms. Personal memories—wedding videos, childhood footage, family reunions—gain new life when upscaled from 480p or 720p to 4K, suitable for large displays without degradation.
The workflow typically involves: obtaining the highest-quality source available (originals rather than compressed copies), importing into an upscaling tool, selecting an appropriate AI model, and processing with conservative enhancement settings to avoid over-interpretation. For particularly damaged footage, applying noise reduction before upscaling prevents the upscaler from amplifying compression artifacts.
Content Creator Applications
YouTubers, social media creators, and streamers can use AI upscaling to repurpose back catalogs or old footage that didn’t meet platform requirements. A creator with 5-year-old 720p YouTube videos can upscale to 4K, then re-upload as premium content. This approach avoids expensive re-shooting while refreshing content for modern audiences.
Creators repurposing archival footage for modern media should note that upscaling before final editing provides more pixels for cropping and adjustments. However, upscaling after careful editing preserves those edits exactly as made, without AI reinterpretation. Most professionals recommend upscaling in stages (2× then 2× again) rather than attempting single large scaling jumps.
Broadcasting and Streaming Services
Broadcasters and streaming platforms increasingly deploy AI upscaling for real-time enhancement of incoming feeds. Live sports, news broadcasts, and streaming content benefit from on-the-fly upscaling that improves perceived quality without requiring expensive re-encoding infrastructure.
Professional broadcast workflows use sophisticated upscaling that operates transparently to the viewer. Incoming 720p feeds are upscaled to 4K using real-time AI, reducing the need for new broadcast equipment while maintaining quality improvements. This particularly benefits international broadcasts where feed quality varies dramatically.
Practical Workflow: Best Practices for Maximum Quality
Starting with the Highest-Quality Source
The fundamental rule of all upscaling work is starting with the highest-quality source available. AI upscaling amplifies what exists in your source material. If you start with a heavily compressed file—like a YouTube video downloaded from the internet—the AI reconstructs compression artifacts along with legitimate detail, resulting in unnatural textures and artificial patterns.
When possible, obtain original uncompressed or lightly compressed source files. Professional video sources often exist as ProRes, DNxHD, or similarly high-quality intermediate formats. Even if compressed sources are all that’s available, choose the least compressed version possible. A source file with 2-3× the bitrate of your final target provides more information for the upscaler to work with.
Choosing the Right AI Model for Your Content
Different AI models optimize for different content types and quality levels. For general upscaling, Topaz’s Artemis model handles footage across quality levels effectively. For particularly high-quality sources, Gaia specializes in detailed reconstruction. For faces, Iris model provides superior facial detail recovery.
Selection also depends on your tolerance for processing time. Faster models produce acceptable results in minutes, while professional-grade models may require hours for feature-length footage. Consider running test clips with different models—a few minutes of experimentation prevents hours of full-resolution rendering.
Avoiding Common Quality-Reducing Mistakes
Never upscale footage that has already been upscaled, as this compounds artificial details with each pass. Each iteration introduces additional hallucinated pixels that may not accurately reflect the original content. If you must make multiple scaling jumps, do them in a single pass with a modern AI tool rather than upscaling upscaled footage.
Over-sharpening is a common mistake. Many users apply additional sharpening filters after upscaling, but modern AI models already include sharpening within their processing. Additional sharpening often produces halos around objects and unnatural edge enhancement. It’s better to disable built-in sharpening in the upscaler and apply any additional sharpening manually with precise control.
Avoid upscaling images with extreme problems—severe motion blur, extreme out-of-focus areas, or massive exposure issues represent truly missing information that no algorithm can recover. Consider alternative source material or accepting quality limitations rather than expecting miracles from upscaling.
File Format and Codec Considerations
When exporting upscaled videos for distribution, choose efficient modern codecs. H.265 (HEVC) provides better compression than H.264, making it ideal for 4K content. For professional post-production, Apple ProRes offers excellent quality-to-file-size balance. For archival storage, ProRes provides minimal quality loss.
For upscaled video destined for streaming, encode to H.264 or H.265 with adaptive bitrate encoding that serves different qualities to different viewers. This allows viewers with limited bandwidth to receive a lower-bitrate version, while high-bandwidth viewers get pristine quality.
Limitations and Challenges: What Upscaling Cannot Do
The Fundamental Information Problem
AI video upscaling, despite its sophistication, cannot create information that doesn’t exist in the source. Extremely blurry footage, extreme out-of-focus areas, and severely degraded content represent fundamental limitations. The upscaler can sharpen edges that are blurred from camera motion or compression, but it cannot recover detail lost due to lens focus problems or motion blur inherent in the original capture.
Similarly, extreme compression artifacts—where original footage was compressed to a very low bitrate—present challenges. The AI may hallucinate details that never existed in the original scene. In these cases, acceptance of quality limitations may be more realistic than expecting miracles.
Computational Requirements and Processing Time
Professional-grade upscaling is computationally intensive. Processing a one-hour 4K video can require many hours on consumer hardware, even with dedicated GPUs. This limits practical applications in real-time streaming scenarios, though cloud-based solutions offset this limitation.
Real-time upscaling during playback remains limited to lower scaling factors and shorter segments. While GPU-assisted upscaling (like NVIDIA RTX Video Super Resolution) can handle real-time playback enhancement, it doesn’t deliver the quality of offline processing.
Motion and Temporal Artifacts
Despite advances in temporal consistency, some scenarios still challenge modern upscalers. Very fast motion, rapid scene changes, and complex camera movements can produce occasional flickering or temporal inconsistencies. Newer models like Upscale-A-Video show dramatic improvements in these areas, but no algorithm is perfect.
Content with many compression artifacts or unusual visual elements may produce unnatural hallucinations where the AI makes incorrect assumptions about what details should exist. Text embedded in video is particularly challenging—upscalers often misread or distort text because training data may not emphasize text preservation.
Future of Video Upscaling: What’s Coming Next
The trajectory of AI video upscaling points toward several exciting developments. Real-time upscaling with AI-powered frame interpolation will enable viewers to watch SD content with 4K quality and smooth motion simultaneously. AI-powered HDR conversion—where SDR (Standard Dynamic Range) video is automatically converted to HDR with realistic highlight and shadow detail—approaches practical implementation.
Object-aware enhancement will recognize specific elements like faces, text, or vehicles, applying targeted upscaling optimized for each object type. This eliminates one-size-fits-all upscaling approaches, allowing each region to be optimized independently.
Integration of super-resolution directly into video encoding will become standard, combining upscaling with other AI coding tools to improve overall compression efficiency. Streaming services will deploy AI upscaling at the edge, applying it during playback on viewer devices rather than in the cloud, reducing infrastructure costs while improving speed.
Read More:How to Instantly Animate Your Old Photos Using AI (Free Tools, No Skills Needed)
Source: K2Think.in — India’s AI Reasoning Insight Platform.