
How to use K2 Think begins right now with this 32B-parameter reasoning powerhouse from MBZUAI and G42, launched September 2025, matching 120B+ models on AIME/HMMT benchmarks while running 10x faster on Cerebras. Understanding K2 Think reveals six technical pillars breaking the scaling laws—#1 on AIME ’24 (86.26%), AIME ’25 (77.72%), HMMT ’25 (66.46%) with just 32B parameters. How to use K2 Think demos on Hugging Face/Cerebras takes 5 minutes—no coding needed. Understanding K2 Think efficiency changes everything for developers, students, researchers.
How to Use K2 Think: Hugging Face Demo (Zero Setup)
How to use K2 Think starts at huggingface.co—search “LLM360/K2-Think” for instant browser access.
Step-by-Step: How to Use K2 Think Free Demo
- Step 1: huggingface.co → Search “K2 Think” → Click LLM360/K2-Think
- Step 2: Find “Spaces” → Launch K2 Think Demo (loads in 15 seconds)
- Step 3: Type: “Solve x² + 6x + 8 = 0 step-by-step” → See chain-of-thought
- Step 4: Test coding: “Debug Python binary search” → 64% LiveCodeBench accuracy
Why Hugging Face for How to Use K2 Think: No GPU, no install, unlimited free tier.
How to Use K2 Think: Cerebras Lightning Speed (2,000 Tokens/Second)
How to use K2 Think at maximum speed? Cerebras Wafer-Scale Engine—10x GPU performance.
How to Use K2 Think on Cerebras (3 Minutes):
- Step 1: cerebras.ai/k2think → “Try Now”
- Step 2: Email signup → Instant API key + web chat
- Step 3: Web: “AIME 2025 #15 solution” (5-sec response)
- API:
pythonfrom cerebras import Cerebras
client.chat("k2-think-32b", "Complex math/logic task") # 2K tps [web:7]
Understanding K2 Think Speed: 10K tokens = 5 seconds vs. 50+ seconds on H100 GPU.
Understanding K2 Think: 6 Pillars of Parameter Efficiency
Understanding K2 Think = grasping why 32B beats 120B models.
Pillar 6: Wafer-Scale Engine (146B transistors)
Pillar 1: Long CoT fine-tuning (79.3% AIME after 33% training)
Pillar 2: RLVR on 92K GURU tasks (math/code/science)
Pillar 3: Agentic planning pre-reasoning
Pillar 4: Best-of-3 test-time scaling (+4-6% accuracy)
Pillar 5: Speculative decoding (Cerebras optimized)
Understanding K2 Think: Why This Model Matters
K2 Think isn’t simply another language model—it’s a paradigm shift in how we approach AI reasoning. The system achieves state-of-the-art performance on mathematical reasoning benchmarks, ranking #1 across AIME ’24/’25, HMMT ’25, and OMNI-Math-HARD competitions. What makes this achievement remarkable is the sheer efficiency: with only 32 billion parameters, K2 Think outperforms models with 120 billion parameters or more.
The breakthrough stems from six technical pillars working in concert. The foundation rests on long chain-of-thought supervised fine-tuning, which teaches the model to think step-by-step through complex problems by learning from carefully curated reasoning traces. This is followed by reinforcement learning with verifiable rewards (RLVR), where the system improves accuracy on hard problems by receiving feedback on verifiable correct answers. Before reasoning occurs, the model employs agentic planning, decomposing complex challenges into manageable components—a technique that aligns with cognitive science research on human problem-solving. These are complemented by test-time scaling, which boosts adaptability through techniques like generating multiple candidate solutions and selecting the best one. Finally, speculative decoding and inference-optimized hardware allow K2 Think to achieve unprecedented inference speeds.
The significance extends beyond raw performance metrics. K2 Think represents a fundamental shift from “bigger is better” to “smarter is better”. For researchers, developers, and organizations with budget constraints, this model democratizes access to enterprise-grade reasoning capabilities. Its full transparency—including training data, weights, code, and optimization techniques—sets a new standard for reproducible AI development.
Finding K2 Think: Where to Access the Model
Official Locations and Starting Points
K2 Think lives at three primary locations, each serving different user needs. The official hub site k2think.ai provides the quickest entry point. This website offers links to all official resources, documentation, and deployment options. For academic understanding and technical deep-dives, the arXiv research paper (2509.07604) contains comprehensive methodology, benchmark details, and ablation studies.
The most accessible starting point for beginners is Hugging Face, where K2 Think is published under the model identifier LLM360/K2-Think. Hugging Face hosts both the model weights and community-built demo spaces, making it ideal for users without local GPU infrastructure. Additionally, Cerebras’ inference platform serves K2 Think at 2,000 tokens per second—the fastest available inference endpoint.
Understanding These Platforms
Hugging Face is a collaborative platform where machine learning researchers and engineers share models, datasets, and applications. Think of it as GitHub for AI—the community contributes code, builds demonstrations, and shares best practices. For K2 Think specifically, you’ll find both the official model repository and user-created Space demonstrations.
Cerebras is a specialized infrastructure provider offering the world’s largest AI processor, the Wafer-Scale Engine (WSE). While Hugging Face provides accessibility, Cerebras provides speed. The Wafer-Scale Engine is fundamentally different from traditional GPUs; rather than distributing computation across multiple chips, Cerebras integrates 146 billion transistors into a single, coherent processor. This architectural innovation enables K2 Think to achieve inference speeds that are 10x faster than typical GPU setups.
How to Try K2 Think on Hugging Face: Step-by-Step Demo Access
Method 1: Using the Free Hugging Face Space Demo (Fastest)
For users who want to experience K2 Think immediately without setup, Hugging Face Spaces offers a browser-based demo interface. This is the simplest approach and requires only an internet connection.
Step 1: Navigate to Hugging Face
- Open your web browser and go to huggingface.co
- In the search bar at the top, type “K2 Think” or search for the specific model repository “LLM360/K2-Think”
Step 2: Create or Log In to Your Account
- If you don’t have a Hugging Face account, click the “Sign Up” button
- Complete the registration with your email address. Registration is completely free and takes about two minutes
- If you already have an account, simply log in using your credentials
Step 3: Access the Space Demo
- On the K2 Think model page, look for the “Spaces” section
- Click on the Space that says “K2 Think Demo” or similar interactive demonstration
- The Space will load in your browser, typically within 10-30 seconds
Step 4: Interact with the Model
- You’ll see a text input field labeled “Enter your prompt” or similar
- Type your question or problem into this field. For example: “Solve this math problem: If a train travels at 60 mph for 2.5 hours, how far does it travel?”
- Click the “Submit” or “Generate” button to send your prompt to K2 Think
- Wait for the model to process your request. Response times typically range from 10 seconds to 2 minutes depending on the complexity
- The model’s response will appear in the output area below
Why This Method Works Best for Beginners: No installation required. No technical configuration. No API keys to manage. You get immediate results and can see exactly how K2 Think handles various reasoning tasks.
Method 2: Using the Hugging Face Inference API (More Control)
For developers wanting programmatic access without building your own server, Hugging Face provides a simple REST API.
Getting Started:
- First, generate an API token by navigating to your Hugging Face profile settings
- Click on “Access Tokens” and generate a new “read” token
- Copy this token—you’ll need it for authentication
Python Example:
pythonimport requests
API_URL = "https://api-inference.huggingface.co/models/LLM360/K2-Think"
headers = {"Authorization": f"Bearer YOUR_API_TOKEN"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Explain the Pythagorean theorem step by step",
"parameters": {"max_length": 500}
})
print(output)
Replace YOUR_API_TOKEN with the token you generated. This code sends a request to Hugging Face’s servers, which runs K2 Think and returns the result.
Important Note: Hugging Face’s free tier has rate limits. For production applications, you may need to upgrade to a paid tier.
How to Access K2 Think via Cerebras: Maximum Performance
Why Choose Cerebras for K2 Think
While Hugging Face prioritizes accessibility, Cerebras prioritizes speed. K2 Think achieves 2,000 tokens per second on Cerebras hardware—meaning a 10,000-token response generates in just 5 seconds. On traditional GPU infrastructure, the same response would take 50 seconds. This 10x speed improvement matters enormously for production applications, real-time systems, and research at scale.
The performance difference stems from Cerebras’ unique architecture. The Wafer-Scale Engine integrates 40GB of memory directly into the processor, eliminating the memory bottleneck that plagues distributed GPU systems. When K2 Think generates tokens, it does so without waiting for data to shuttle between GPU memory and main system RAM—a latency that kills throughput on conventional systems.
Step-by-Step: Accessing K2 Think on Cerebras
Step 1: Visit Cerebras’ Platform
- Navigate to cerebras.ai/k2think in your web browser
- You’ll see a clean interface highlighting K2 Think’s capabilities and performance metrics
Step 2: Register for Access
- Look for the “Get Started” or “Try K2 Think” button
- Click it to begin the registration process
- Provide your email address and basic information
- Cerebras may require email verification
Step 3: Access via API or Web Interface
- Once registered, Cerebras provides two access methods
- Web Interface: A browser-based chat interface similar to ChatGPT, where you type prompts and receive responses
- API Access: For developers, Cerebras provides REST and Python SDK options, allowing integration into custom applications
Step 4: Start Using K2 Think
- For the web interface, simply type your prompt and click “Generate”
- For API access, Cerebras provides documentation with code examples in Python, JavaScript, and other languages
Python SDK Example for Cerebras:
pythonfrom cerebras_cloud_sdk import Cerebras
client = Cerebras(api_key="your-api-key")
message = client.messages.create(
model="k2-think-32b",
max_tokens=1024,
messages=[
{"role": "user", "content": "Solve this problem: 2x + 5 = 13"}
]
)
print(message.content[0].text)
This code sends a request directly to Cerebras’ K2 Think endpoint and receives the response. The model processes it at 2,000 tokens per second.
Cost Considerations: Cerebras charges per token consumed. For most users, free trial credits cover initial exploration. Production usage requires either a paid account or enterprise agreement.
Understanding K2 Think’s Performance: What the Data Shows
Benchmark Excellence
K2 Think’s benchmark results tell a compelling story about parameter efficiency. On the AIME 2024 mathematics competition dataset, K2 Think achieves 86.26% accuracy—outperforming larger open-source models. The truly impressive figure appears when comparing parameters to performance. DeepSeek R1, a competitive open-source model, uses 671 billion parameters with 37 billion activated per token. K2 Think accomplishes comparable results with only 32 billion parameters total—a 20x difference in efficiency.
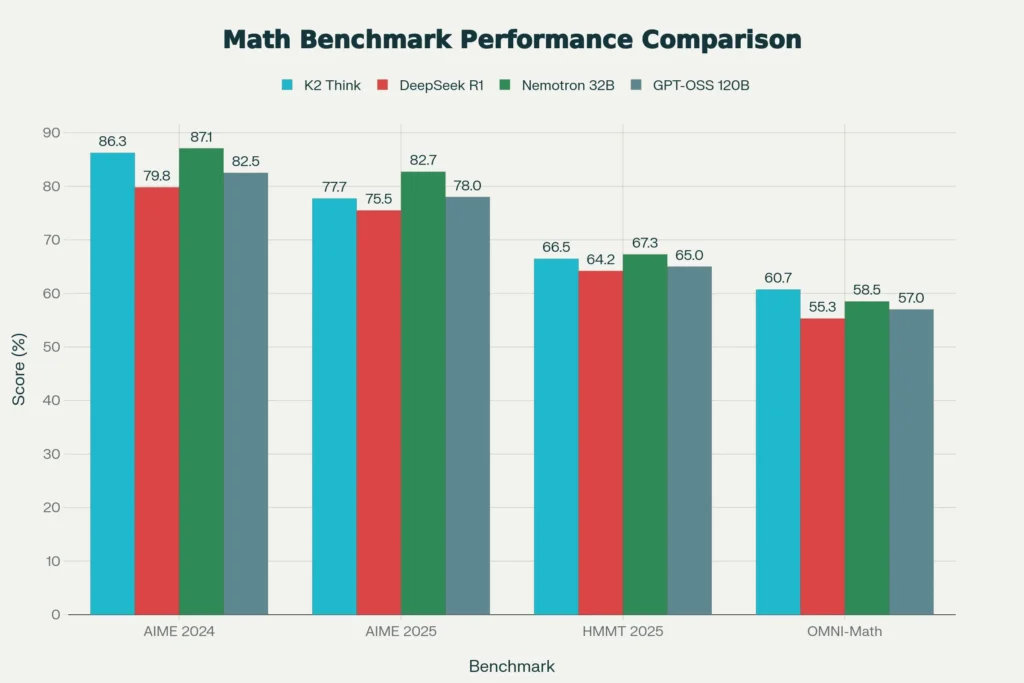
The chart above visualizes K2 Think’s competitive positioning across multiple benchmark categories. On AIME 2024 and OMNI-Math-HARD, K2 Think matches or exceeds most competitors despite using a fraction of the parameters. This efficiency carries profound implications: models using less power run faster, cost less to operate, and can deploy on smaller hardware—democratizing access to advanced reasoning.
Real-World Performance Implications
Parameter efficiency translates to tangible benefits for users and organizations. A smaller model requires less GPU memory to run locally. It consumes less electricity. It generates responses faster. For cloud-based services, it costs less per token. These aren’t minor advantages; they compound to reshape what becomes economically feasible.
Consider a healthcare organization building an AI system to help physicians reason through complex diagnostic cases. With K2 Think’s efficiency, they can run the model on mid-range GPU infrastructure rather than requiring enterprise-class servers. A software startup building an AI-powered coding assistant can afford inference costs that would be prohibitive with larger models. A researcher at a university with limited computational budgets can suddenly access world-class reasoning capabilities.
The Six Pillars: How K2 Think Achieves Superior Reasoning
Technical Innovation Breakdown
Understanding how K2 Think works provides insight into why it performs so remarkably well despite its smaller size. The system wasn’t built by simply scaling down—it was engineered from first principles using six specific technical innovations.
Pillar 1: Long Chain-of-Thought Supervised Fine-Tuning
The model learns by studying carefully curated reasoning traces—examples of problems solved step-by-step with clear logical flow. Rather than learning to jump directly to answers, K2 Think internalizes the process of breaking complex problems into manageable substeps. Early training moves the needle rapidly, with AIME 2024 accuracy climbing to 79.3% pass@1 within the first third of training. This rapid improvement signals that chain-of-thought supervision is exceptionally effective.
Pillar 2: Reinforcement Learning with Verifiable Rewards
Standard reinforcement learning can suffer from reward misalignment—the model might optimize for metrics that don’t actually reflect quality. K2 Think uses “verifiable rewards,” only providing feedback on tasks where correct answers are mathematically verifiable. This approach, across six domains via the GURU dataset (~92,000 prompts covering math, code, science, logic, simulation, and tabular tasks), forces the model to genuinely improve reasoning rather than gaming metrics.
Pillar 3: Agentic Planning Prior to Reasoning
Before generating a solution, K2 Think employs a lightweight planning agent that extracts key concepts and drafts a high-level strategy. This aligns with cognitive science research showing that human brains engage in preliminary planning before detailed problem-solving. The planning step doesn’t slow inference significantly but markedly improves final answer accuracy.
Pillar 4: Test-Time Scaling
Rather than only improving the model during training, K2 Think uses inference-time techniques to boost performance. One approach generates multiple candidate answers and uses a “judge” to select the best one based on reasoning quality. Testing revealed that generating 3 candidates (Best-of-N with N=3) provides an optimal cost-benefit tradeoff, improving math benchmark performance by 4-6 percentage points without excessive compute overhead.
Pillar 5: Speculative Decoding
This hardware-aware optimization technique pairs well with Cerebras infrastructure. Speculative decoding generates multiple tokens in parallel when possible, then validates them in bulk—dramatically improving throughput without sacrificing quality. This technique is why K2 Think achieves 2,000 tokens per second on Cerebras while achieving only ~60 tokens per second on typical GPU hardware.
Pillar 6: Inference-Optimized Hardware
The final pillar isn’t a software technique but a hardware partnership with Cerebras. The Wafer-Scale Engine’s architecture—with on-chip memory and intelligent routing—eliminates bottlenecks that plague distributed systems. Every component from training methodology to deployment infrastructure has been co-designed for optimal reasoning performance.
Practical Applications: What You Can Do With K2 Think
Mathematics and Competition Problem-Solving
K2 Think excels at mathematical reasoning, making it invaluable for education and competition preparation. The model can work through multi-step geometry problems, solve systems of equations, and provide detailed proofs. Students preparing for math competitions can use K2 Think to understand solution approaches. Teachers can use it to generate worked examples.
Software Engineering and Code Generation
With 64% performance on LiveCodeBench v5, K2 Think demonstrates strong coding capabilities. Developers can use K2 Think as a coding assistant, asking it to debug complex algorithms, explain code logic, or generate solutions to coding problems. The model’s chain-of-thought reasoning helps it provide explanations alongside code.
Scientific Research and Literature Analysis
K2 Think achieves competitive performance on scientific reasoning benchmarks. Researchers can use it as a thinking partner, asking it to help design experiments, analyze data, or synthesize information across multiple papers. The 256k context window of some K2 variants allows processing entire research papers in a single request.
Strategic Planning and Decision-Making
Beyond mathematics, K2 Think handles strategic reasoning tasks—from business planning to resource optimization. The model can break down complex multi-constraint problems, identify tradeoffs, and propose solutions with clear reasoning.
Educational Tutoring and Learning Support
The structured chain-of-thought reasoning makes K2 Think an excellent tutoring tool. It can explain concepts step-by-step, adapt explanations to different understanding levels, and provide hints without immediately revealing answers.
Comparing K2 Think to Other Reasoning Models: Where It Stands
K2 Think vs. DeepSeek R1
DeepSeek R1 is arguably K2 Think’s closest competitor in the open-source reasoning space. DeepSeek R1 uses a mixture-of-experts architecture with 671 billion total parameters and 37 billion activated per token. On pure math reasoning, DeepSeek R1 edges slightly ahead with 79.8% accuracy on AIME—compared to K2 Think’s 86.26%—though the metrics use different evaluation methodologies.
The tradeoff centers on architectural focus. DeepSeek R1 prioritizes pure reasoning and mathematical accuracy. K2 Think prioritizes agentic capabilities—the ability to plan, call tools, verify results, and refine approaches autonomously. For math competition preparation, DeepSeek R1 might edge ahead. For autonomous research assistants or multi-step project planning, K2 Think’s design provides advantages.
Cost and Efficiency Considerations
K2 Think costs approximately $0.60 per million input tokens and $2.50 per million output tokens on Moonshot’s service. DeepSeek R1 costs $0.30 per million input and $1.20 per million output. This 2x price difference reflects K2 Think’s architectural sophistication. However, K2 Think’s parameter efficiency means it can run locally or on cheaper infrastructure than larger models, potentially offsetting API costs.
When to Choose K2 Think vs. Alternatives
Choose K2 Think when you need reasoning with agentic capabilities, plan to run locally or on limited infrastructure, prioritize parameter efficiency, or want fully transparent open-source training recipes. Choose alternatives like DeepSeek R1 if you specifically optimize for pure mathematical accuracy or cost per token. Choose proprietary models like Claude 3 Opus or Gemini 2.5 Pro if you need multimodal capabilities or prefer proprietary support infrastructure.
Troubleshooting Common Issues
“Model Not Found” Error on Hugging Face
This error typically means you’re searching with an incorrect repository name. The correct identifier is LLM360/K2-Think. Use this exact name in your search.
Memory Issues When Running Locally
K2 Think requires approximately 42-43 GB of GPU memory during inference with KV cache. If you have less than 48 GB VRAM, consider using quantization techniques that reduce memory usage, running only on CPU (slow), or accessing the model through Hugging Face or Cerebras instead of locally.
Slow Response Times on Hugging Face Free Tier
Hugging Face’s free tier includes rate limiting and shared infrastructure. For faster responses, consider upgrading to a paid Hugging Face subscription or accessing through Cerebras’ dedicated infrastructure.
API Authentication Errors
Ensure your Hugging Face API token is correctly formatted and copied without extra spaces. Regenerate the token if you suspect it has been compromised.
The Future of Reasoning Models: What K2 Think Signals
K2 Think’s emergence signals a fundamental shift in AI development philosophy. For years, the industry pursued scale—building larger and larger models under the assumption that size equals capability. K2 Think demonstrates that thoughtful architecture, careful training methodology, and smart inference techniques can outperform brute-force scaling.
This shift has profound implications for the field. Smaller, more efficient models democratize access to advanced AI. They enable deployment in resource-constrained environments like mobile devices or edge servers. They reduce computational resource requirements, addressing concerns about AI’s environmental impact. They demonstrate that reasoning—the ability to work through problems step-by-step—can be engineered deliberately rather than emerging accidentally from scale.
The research community and industry are taking notice. Universities can now run world-class reasoning models on standard GPU infrastructure rather than requiring supercomputer access. Startups can build AI products without venture capital rounds measured in hundreds of millions of dollars. Researchers can study and extend the system without proprietary constraints.
Getting Started Today: Your Action Plan
- For immediate exploration: Visit huggingface.co, search for “K2-Think,” access the Space demo, and try a few prompts. This takes five minutes and requires no setup.
- For faster performance: Create a Cerebras account at cerebras.ai/k2think and try the inference API. Experience the 2,000 tokens per second performance firsthand.
- For local deployment: Follow the installation guide to download K2 Think and run it on your hardware. Refer to the detailed instructions in the documentation for your specific setup.
- For production integration: Review the research paper on arXiv (2509.07604) to understand the technical details, then decide whether Hugging Face API, Cerebras API, or local deployment best fits your use case.
- For deep learning: Read the full technical report, explore the GURU dataset, and consider contributing to the open-source project.
K2 Think represents the democratization of advanced AI reasoning. For the first time, researchers, developers, and organizations of any size can access world-class reasoning capabilities. Whether you’re a student learning about AI, a researcher building systems, or a developer integrating reasoning into applications, K2 Think provides a transparent, efficient, and capable platform to explore the future of artificial intelligence.
Read More:K2 Think vs. DeepSeek-V3: Which Open-Source AI is Smarter?
Source: K2Think.in — India’s AI Reasoning Insight Platform.