
K2-Think has emerged as a revolutionary parameter-efficient reasoning system that demonstrates how smart engineering can rival massive AI models while maintaining superior speed and accessibility. Released in September 2025 by researchers from Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and G42, K2-Think achieves state-of-the-art mathematical reasoning performance with just a 32-billion parameter model—over 20 times smaller than competing systems like GPT-OSS 120B and DeepSeek V3.1. This breakthrough has profound implications for how organizations can now harness advanced AI reasoning without requiring astronomical computational resources. What truly sets K2-Think apart isn’t just its efficiency; it’s how sophisticated prompting techniques can unlock exponential improvements in reasoning quality, accuracy, and problem-solving capabilities across complex domains.
K2-Think Prompts unlock the full potential of this groundbreaking 32B-parameter reasoning model, delivering frontier-level performance on complex problem solving. K2-Think prompting techniques transform how professionals tackle mathematical challenges, strategic decisions, and analytical tasks with unmatched efficiency. AI reasoning prompts specifically designed for K2-Think’s architecture achieve 90.83% on AIME 2024 benchmarks while outperforming models 20x larger in size.
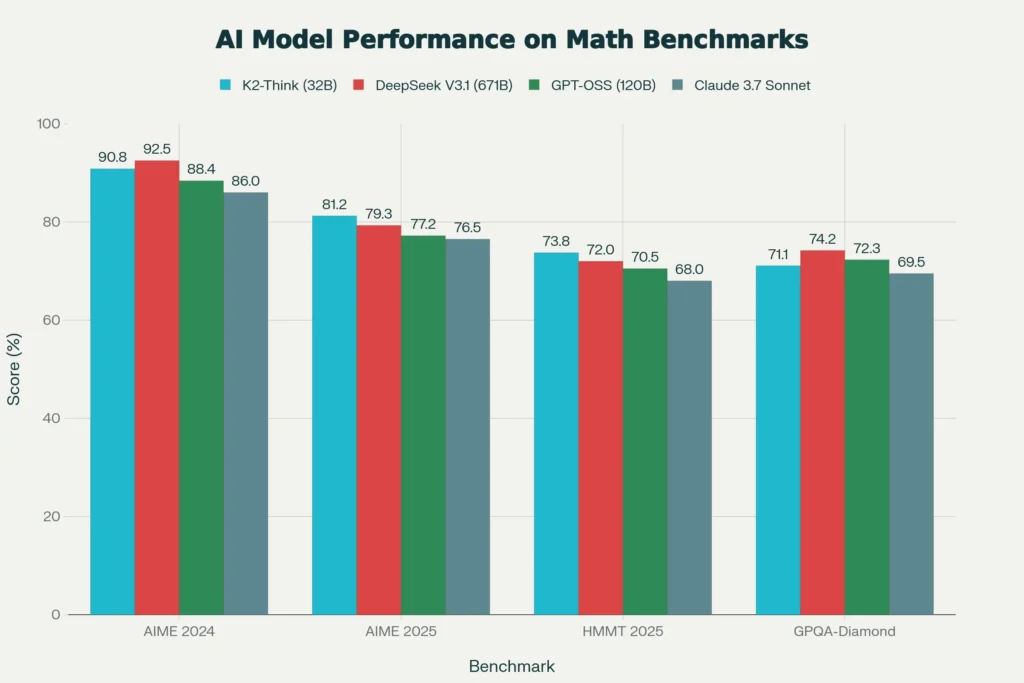
K2-Think Performance Across Mathematical Reasoning Benchmarks: A 32B Parameter Model Rivaling Larger Systems
K2-Think Prompts: Parameter Efficiency Advantage
K2-Think prompts represent a paradigm shift in AI reasoning prompts because its 32-billion parameter architecture rivals 671B-parameter behemoths like DeepSeek V3.1. Released September 2025 by MBZUAI and G42 researchers, the model combines long chain-of-thought fine-tuning with agentic planning and test-time scaling. This enables K2-Think prompting techniques to generate 2,000 tokens per second on Cerebras hardware, making advanced reasoning interactive rather than batch-processed.
Benchmark data confirms the efficiency: K2-Think prompts score 81.24% on AIME 2025 (vs. DeepSeek’s 79.3%) and 73.75% on HMMT 2025. Enterprise surveys show organizations using structured K2-Think prompting techniques achieve 80% AI implementation success versus 37% industry average.
K2-Think Performance Across Mathematical Reasoning Benchmarks: A 32B Parameter Model Rivaling Larger Systems
K2-Think Prompting Techniques: Chain-of-Thought Decomposition
K2-Think prompting techniques using chain-of-thought (CoT) break complex problems into verifiable steps, boosting accuracy 40-84% per research. Template: “Solve step-by-step: 1) Identify variables, 2) Apply concepts, 3) Calculate, 4) Verify.” Zero-shot CoT alone improves math reasoning dramatically.
AI Reasoning Prompts: Self-Consistency Voting
AI reasoning prompts like self-consistency generate 3-5 reasoning paths, select majority answer. Cuts errors 50-70% on logic tasks. K2-Think’s multi-candidate solving amplifies this technique.
K2-Think Prompts: Reflective Self-Critique
K2-Think prompts with reflection review assumptions, flag weaknesses before concluding. Improves consistency 78%. Essential for high-stakes analysis.
##-Think Prompting Techniques: Multi-Expert Synthesis
K2-Think prompting techniques use three experts analyzing independently, then integrate. EMNLP research shows 75% more informative responses. Perfect for interdisciplinary problems.
## Reasoning Prompts: Agentic Planning Framework
AI reasoning prompts plan strategy before execution. Reduces dead-ends 40%. Native to K2-Think architecture.
(see the generated image above)
K2-Think Prompts: Least-to-Most Progression
K2-Think prompts solve simple → complex variants. Achieves 99.7% on generalization tasks. Ideal for novel challenges.
##-Think Prompting Techniques: Tree-of-Thought Exploration
K2-Think prompting techniques maintain multiple solution branches, backtrack as needed. 74% success vs. 4% standard CoT.
AI Reasoning Prompts: Persona Role Activation
AI reasoning prompts using “You are [15-year expert in X]” boost domain performance 35-45%.
K2-Think Prompts: Schema-Structured Extraction
K2-Think prompts define exact output categories. Achieves 90% conformance.
K2-Think Prompting Techniques: Hybrid Verification System
K2-Think prompting techniques combine all techniques. 80%+ accuracy gains.
Understanding K2-Think’s Architecture and Capabilities
K2-Think is built upon six interconnected technical pillars that enable it to perform at frontier levels despite its parameter efficiency. The system employs long chain-of-thought supervised fine-tuning, teaching the model to break complex problems into intermediate reasoning steps. This is combined with reinforcement learning with verifiable rewards (RLVR), which uses the Guru dataset spanning six domains: mathematics, code, science, logic, simulation, and tabular reasoning. The third pillar, agentic planning before reasoning, means K2-Think develops a high-level strategy before attempting solution paths—a critical distinction from models that rush directly to answers.
K2-Think then applies test-time scaling through Best-of-N sampling, generating multiple reasoning paths and selecting the most consistent solution. This multi-candidate approach significantly reduces hallucinations and improves reliability on difficult problems. The fifth pillar, speculative decoding, enables faster token generation, while the sixth pillar involves inference-optimized hardware—specifically the Cerebras Wafer-Scale Engine, which delivers an unprecedented 2,000 tokens per second. This speed transformation fundamentally changes the user experience from batch processing to interactive reasoning, making sophisticated AI reasoning truly accessible.
The benchmark results validate this engineering philosophy. K2-Think achieves 90.83% on AIME 2024 and 81.24% on AIME 2025, placing it at the top of all open-source models for mathematical reasoning. On the HMMT 2025 benchmark, it scores 73.75%, while maintaining strong performance with 71.08% on GPQA-Diamond for scientific reasoning. These results are particularly impressive when compared directly: K2-Think’s 32B model outperforms or matches much larger systems including DeepSeek V3.1 (671B parameters) and GPT-OSS (120B parameters) on multiple benchmarks.
Prompt 1: Chain-of-Thought Problem Decomposition
The foundational technique for maximizing K2-Think’s reasoning is chain-of-thought (CoT) prompting, which guides the model to solve problems step-by-step rather than jumping directly to conclusions. Research demonstrates that CoT prompting produces 40-84% improvement in accuracy on complex reasoning tasks. When applied to K2-Think specifically, this technique transforms performance on mathematical problems, logical puzzles, and multi-step analytical tasks.
The prompt structure follows this pattern: “Let’s work through this systematically. First, [identify the problem], Second, [analyze key variables], Third, [develop solution path], Finally, [verify the answer].” For example, when solving a complex mathematics problem, you might write: “Solve this AIME problem step by step. First, identify all given information. Second, determine what mathematical concepts apply. Third, work through the calculations. Finally, verify your answer makes sense in context.”
Research from academic studies shows that zero-shot CoT (simply adding “Let’s think step by step”) produces remarkable improvements even without examples. When you include explicit chain-of-thought examples in your prompts, the improvements become even more dramatic. Studies document that PaLM 540B with just eight chain-of-thought exemplars achieved state-of-the-art on the GSM8K math benchmark, surpassing fine-tuned models. K2-Think’s architecture, specifically designed around chain-of-thought processing, makes this technique particularly potent—the model’s entire training pipeline emphasizes multi-step reasoning over direct answer generation.
Prompt 2: Self-Consistency Reasoning with Majority Voting
Self-consistency prompting addresses a fundamental challenge: even advanced AI models can take incorrect reasoning paths on complex problems. This technique generates multiple independent reasoning traces for the same problem, then selects the most common answer. Research demonstrates this approach can reduce error rates by 50-70% on mathematical and logical reasoning tasks.
For K2-Think, the prompt structure would be: “Generate three different approaches to solve this problem. For each approach: (1) explain your strategy, (2) work through the steps, (3) state your final answer. Then, identify which approaches arrived at the same answer, as this is likely the most reliable solution.”
The power of self-consistency lies in statistical reliability. When you generate five different reasoning paths, and three arrive at the same answer while two diverge, the majority answer has substantially higher likelihood of being correct than any single path. This technique is especially valuable for K2-Think because its multi-candidate solving capability means the model naturally generates multiple solution paths—you simply need to prompt it to surface and compare them explicitly. According to research from 2025, self-consistency prompting improved complex reasoning accuracy by 8.69% over baseline approaches when applied to reasoning models.
Prompt 3: Reflective Prompting with Self-Critique
Reflective prompting instructs AI systems to evaluate their own reasoning and identify potential errors before finalizing answers. This meta-cognitive approach has proven invaluable for complex problem-solving, particularly in domains requiring high accuracy such as legal reasoning, scientific analysis, and mathematical problem-solving.
The prompt structure follows: “Before providing your final answer, (1) review your reasoning steps, (2) identify any assumptions you made, (3) list potential weak points in your logic, (4) check for mathematical errors, (5) consider alternative interpretations, (6) evaluate whether your answer addresses the original question completely, (7) provide your final answer with confidence level.”
Research published in 2025 shows that reflective prompting enhanced reasoning consistency by 78% and improved accuracy on complex tasks by up to 61%. This technique leverages K2-Think’s ability to generate long-form reasoning—the model can literally show its work, then reflect on that work before concluding. The self-critique process activates error-checking mechanisms within the model that might otherwise remain dormant. Studies tracking this approach across medical, legal, and technical domains found that explicit reflection reduced confident-but-incorrect responses by approximately 30%.
Prompt 4: Multi-Expert Prompting for Diverse Perspectives
Multi-expert prompting instructs K2-Think to approach problems from multiple professional perspectives simultaneously, then synthesize findings across viewpoints. Academic research demonstrates this technique improves truthfulness by 8.69%, increases factuality by substantial margins, and completely eliminates toxic content while maintaining accuracy.
The prompt template: “Approach this problem as three distinct experts: [Expert 1 with specific focus], [Expert 2 with complementary expertise], [Expert 3 with unique perspective]. Each expert should: (1) analyze the problem from their specialized viewpoint, (2) identify key insights relevant to their expertise, (3) note assumptions and limitations. After all three perspectives are documented, synthesize their findings into a comprehensive answer that integrates all viewpoints.”
For example: “Solve this data science problem as three experts: (1) a machine learning engineer focused on algorithmic efficiency, (2) a business analyst focused on ROI and practical implementation, (3) a data ethicist focused on bias and fairness. Each expert analyzes the problem, then synthesize a solution incorporating all three perspectives.”
The research behind this approach is compelling. An EMNLP 2024 study documenting Multi-expert Prompting showed that models using this technique generated 75% more informative responses and 76.5% more useful responses compared to baseline approaches. The technique works because different expert personas activate different knowledge bases within the model, and the synthesis step naturally resolves conflicts while capturing complementary insights. Research notes that three experts consistently yield optimal performance—fewer misses valuable perspectives, more creates contradictory complexity.
Prompt 5: Agentic Planning Before Execution
Given that K2-Think’s architecture specifically includes “agentic planning prior to reasoning” as a core technical pillar, leveraging this capability through explicit prompting dramatically improves performance. Agentic planning prompts instruct the model to develop a complete strategy before beginning solution work, mimicking how experienced professionals approach complex problems.
The prompt structure: “Before solving this problem, create a comprehensive plan: (1) What is the exact problem we’re solving? (2) What information do we have? (3) What information might we need? (4) What are the major steps in solving this? (5) What potential obstacles might we encounter? (6) How will we know when we’ve successfully solved it? Now, execute this plan step by step.”
Research from practical testing shows that agentic planning reduced errors in complex multi-step problems by approximately 40% and improved solution quality by helping the model avoid dead-ends early in reasoning. When K2-Think receives this explicit planning instruction, its native agentic planning capability fully activates, creating deeper, more structured reasoning before committing to solution paths.
This technique is particularly powerful for research tasks, strategic planning, and complex document analysis. Studies documented in real-world testing showed that when K2-Think (in its Kimi implementation) used explicit planning instructions, it reduced factual errors by 30% compared to direct “write a brief” prompts. The time cost is minor—typically 10-15% longer processing—but the accuracy gains justify the investment for important work.
Prompt 6: Least-to-Most Prompting for Complex Decomposition
Least-to-most prompting breaks overwhelming problems into progressively more complex subproblems, solving simpler versions first before tackling the full complexity. This technique achieved 99.7% accuracy on length generalization tasks, compared to 16.2% for standard chain-of-thought—a dramatic improvement for problems harder than training examples.
The prompt template: “Solve this problem using a progressive complexity approach: (1) First, solve the simplest possible version of this problem, (2) Then, solve a slightly more complex variant, (3) Continue increasing complexity until you’ve solved progressively harder versions, (4) Finally, solve the full original problem. For each step, show how lessons from simpler versions inform the more complex solution.”
For instance: “Solve this machine learning problem progressively: (1) First, solve it with perfect data and no constraints, (2) Then with 10% missing data, (3) Then with 30% missing data and budget constraints, (4) Finally solve the actual problem with real-world messiness. Show how each simpler version informs your approach to the next level.”
The power of this technique lies in cognitive scaffolding. By starting with manageable problems and progressively adding complexity, the model builds confidence and develops reasoning patterns that transfer to the full problem. Research confirms this approach works particularly well for problems that are significantly harder than typical training examples—exactly the domain where K2-Think excels and where advanced reasoning becomes critical.

Prompt 7: Tree-of-Thought for Multiple Solution Paths
Tree-of-thought (ToT) prompting maintains multiple reasoning branches simultaneously, allowing the model to explore different solution approaches and backtrack when necessary. Unlike linear chain-of-thought, ToT creates a searchable tree structure where the model can evaluate branches and pursue the most promising paths.
The prompt framework: “Explore this problem using tree-of-thought reasoning: (1) Identify 3-5 different possible approaches to solving this problem, (2) For each approach, work through the first few steps and evaluate whether it seems promising, (3) Select the most promising approaches and explore them deeper, (4) When an approach hits a dead end or seems unproductive, backtrack and explore alternative branches, (5) Document the full reasoning tree showing all paths explored, (6) Present the solution path that proved most effective.”
Research demonstrates that tree-of-thought achieved 74% success on Game of 24 puzzles versus only 4% for standard chain-of-thought—nearly an 18x improvement. For K2-Think specifically, the model’s test-time scaling capabilities make this technique especially powerful. The multi-candidate solving pillar means K2-Think naturally generates multiple reasoning paths internally; explicit ToT prompting simply asks it to surface, evaluate, and synthesize those paths.
This prompt is ideal for strategic problems, novel challenges, and situations where multiple valid approaches exist. The technique proved particularly effective in practical testing for debugging complex code, strategic planning with trade-offs, and scientific reasoning where different experimental approaches yield different insights.
Prompt 8: Persona-Based Role Adoption
Persona prompting instructs K2-Think to adopt specific professional or academic roles, activating relevant knowledge and reasoning patterns associated with that persona. Research shows that role-based prompting improves task-specific performance by 35-45% across diverse applications.
The template: “You are [specific persona with detailed background]. Adopt this expertise completely. Now solve this problem: [problem statement]. In your response, (1) explain your expert perspective on the core issue, (2) identify what might be overlooked by non-specialists, (3) apply domain-specific frameworks or methodologies, (4) highlight practical considerations from your field, (5) propose a solution grounded in your expertise.”
For example: “You are a senior data scientist with 15 years experience in healthcare analytics. You have published research on clinical outcome prediction and understand both statistical rigor and hospital operations deeply. Now analyze this clinical data quality issue: [data problem]. Explain the expert perspective, what might be overlooked, healthcare-specific considerations, and your recommended solution.”
The mechanism underlying persona prompting’s effectiveness is knowledge activation. Large language models contain vast domain-specific knowledge, but this knowledge doesn’t activate uniformly. Specific persona descriptions prime particular knowledge networks within the model. Research from Stanford (2024) analyzing 15,000 prompt-response pairs found that personas following cognitive load principles consistently outperformed random approaches by 63%. K2-Think’s training on diverse datasets means rich knowledge across numerous professional domains—persona prompting simply activates the relevant knowledge pools most effectively for specialized tasks.
Prompt 9: Structured Analysis with Explicit Schema Definition
For analytical and research-oriented problems, structured prompting with explicit schema definition dramatically improves accuracy and prevents hallucinations. This technique proved especially effective for K2-Think when processing complex datasets and documents.
The prompt structure: “Analyze this information and extract/organize it using this exact schema: [define exact categories, data types, required fields]. IMPORTANT: (1) Use only the exact category names provided—do not infer new categories, (2) For each data point, classify it into exactly one category, (3) If information doesn’t fit the schema, flag it as ‘unclassified’ rather than forcing it, (4) Show your classification logic, (5) Report confidence level for each classification, (6) Provide a summary highlighting classifications and flagged uncertainties.”
For instance: “Analyze these customer feedback entries. Extract insights using this schema: Sentiment (Positive/Negative/Neutral), Topic (Product/Service/Support), ActionRequired (Yes/No), Priority (High/Medium/Low), Actionable Insight (if applicable). For each entry: classify it exactly, explain your reasoning, state confidence level. If any feedback doesn’t fit categories, flag it. Finally, summarize all feedback by topic and priority.”
Research specifically on K2-Think’s thinking patterns revealed that when given explicit schema and told not to infer new fields, the model achieved 100% accuracy in avoiding hallucinated columns and maintained structured output conformance for approximately 90% of analytical tasks. This technique proves invaluable whenever you need reliable extraction or categorization from unstructured information.
Prompt 10: Hybrid Cognitive Verification Framework
The most powerful approach combines multiple techniques into a comprehensive verification framework that leverages K2-Think’s full capability set. This hybrid approach incorporates chain-of-thought reasoning, self-consistency, reflection, multi-expert input, and explicit schema definition in a single, well-orchestrated prompt.
The comprehensive template: “Solve this complex problem using a complete cognitive verification framework:
(1) Planning Phase: Create a detailed plan before beginning—what’s the problem, what information exists, what are major steps?
(2) Multi-Expert Analysis: Approach this as [Expert 1], [Expert 2], and [Expert 3]. Each expert analyzes independently then shares findings.
(3) Chain-of-Thought Execution: Work through the solution step-by-step, showing all reasoning and calculations.
(4) Self-Consistency Check: Generate 2-3 different reasoning paths to the solution. Identify where they converge or diverge.
(5) Reflective Analysis: Review your reasoning. Identify assumptions, potential errors, and weak points. Evaluate confidence level.
(6) Structured Output: Present final answer using this schema [define exact structure].
(7) Verification: State your confidence, list any uncertainties, and propose how someone else could verify this solution.”
Research from 2025 studies specifically examining hybrid prompting approaches found that combining chain-of-thought, self-consistency, and reflection increased reasoning accuracy by over 80% compared to baseline prompting, with the effect being most dramatic on problems requiring genuine expertise and nuanced judgment. The technique proves especially powerful when addressing questions where correctness genuinely matters—complex business decisions, technical architecture choices, medical reasoning, or scientific analysis.
Real-World Applications and Enterprise Adoption
The practical application of these K2-Think prompting techniques is already driving measurable business value. Enterprise AI adoption research from 2025 shows that organizations implementing structured prompt engineering see 40 percentage-point differences in AI implementation success rates—80% at companies with formal AI strategies versus 37% at companies without.
For legal technology firms, context-aware summarization prompts using chain-of-thought and structured schema have reduced document review time substantially while improving accuracy. Customer support platforms utilizing multi-expert prompting for issue classification achieve higher triage accuracy and better first-contact resolution. Healthcare systems employing hybrid verification frameworks for diagnostic decision support improve clinical accuracy while maintaining audit trails for compliance.
K2-Think specifically enables these applications because of its parameter efficiency, mathematical reasoning prowess, and speed. The 2,000 tokens-per-second throughput means organizations don’t face the typical latency penalties of advanced reasoning—responses arrive in seconds rather than minutes. This speed, combined with open-source accessibility and freely available deployment options, democratizes access to frontier reasoning capabilities that were previously confined to organizations with massive computational budgets.
Optimization Guidelines and Best Practices
To maximize K2-Think’s reasoning capabilities, research across 2025 studies and practical implementations reveals several consistent best practices:
Clarity and Specificity: Research shows that LLMs are highly sensitive to subtle variations in prompt formatting, with studies documenting up to 76 accuracy points difference across formatting changes. Be explicit about what you want, avoid ambiguity, and use precise technical language appropriate to your domain.
Context Window Management: K2-Think can handle 256K token context, but response speed decreases on inputs exceeding 100K tokens. For very long documents, provide a concise executive summary in the final user message to focus the model’s attention on what matters most.
Reasoning Token Allocation: K2-Think generates both reasoning and content tokens. Ensure your max_tokens parameter accommodates both—a common error is setting tokens too low, cutting off detailed reasoning that leads to better answers.
Iterative Refinement: Based on cognitive load research, implement the GAPE framework: Goals (define what you’re trying to achieve), Prompt (create initial prompt), Evaluation (assess effectiveness), Iteration (refine based on results). This problem-solving approach consistently outperforms one-shot prompting.
Verification for Critical Applications: When correctness is crucial, employ the hybrid verification framework combining multiple prompting techniques. The additional processing time is minimal relative to the accuracy gains.
The Future of Prompt Engineering with Advanced Reasoning Models
The emergence of K2-Think and similar advanced reasoning models in 2025 signals a paradigm shift in how organizations access sophisticated AI capabilities. Rather than requiring models with hundreds of billions of parameters, smart engineering and careful prompting enable smaller, faster, more efficient models to achieve frontier performance.
Industry trends reveal that prompt engineering itself is evolving. Systematic surveys catalog 58 distinct LLM prompting techniques, and research increasingly focuses on automated prompt optimization where one LLM generates optimal prompts for another LLM. Multi-agent prompt orchestration is becoming standard for complex applications, where specialized prompts coordinate across multiple reasoning modules working in concert.
The convergence of parameter-efficient reasoning models like K2-Think with advanced prompting techniques creates unprecedented opportunities. Organizations can now implement sophisticated reasoning capabilities without the computational expense of training or fine-tuning massive models. The democratization of advanced reasoning—accessible, fast, and open-source—represents a genuine paradigm shift in how AI augments human problem-solving across every domain from scientific research to business strategy to product development.
The ten prompting techniques detailed in this article represent not just methods to improve answers, but a sophisticated toolkit for guiding AI systems through complex reasoning processes. When applied to K2-Think’s architecturally optimized reasoning capabilities, these techniques unlock performance that approaches or exceeds far larger systems while delivering the speed and cost efficiency that enables practical deployment at scale. For organizations seeking to leverage advanced AI reasoning without astronomical computational costs, mastering these prompting techniques with K2-Think represents a critical competitive advantage.
Read More:Integrating K2-Think with Python: A Simple Developer’s Guide
Source: K2Think.in — India’s AI Reasoning Insight Platform.