
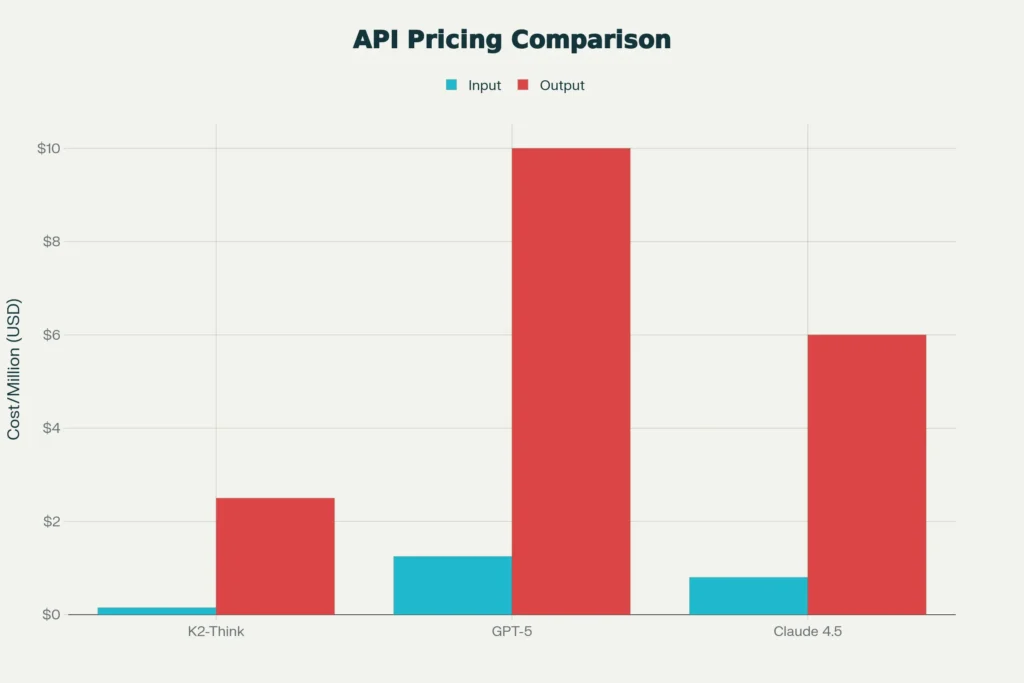
K2-Think with Python makes advanced AI reasoning accessible to every developer through simple OpenAI-compatible API calls. This 32B parameter Mixture-of-Experts model from Moonshot AI—launched November 2025—matches GPT-5 performance while costing 4-8x less ($0.15/M input tokens, $2.50/M output tokens).
K2-Think with Python excels at autonomous agents handling 200-300 sequential tool calls, perfect for research automation, document analysis, and complex problem-solving. Your existing OpenAI SDK code works immediately, delivering transparent reasoning chains you can inspect and debug.
Why K2-Think with Python Dominates Agentic Workflows
K2-Think with Python integration requires zero code rewrites—change only the model name in your OpenAI client:
pythonclient = OpenAI(base_url="https://openrouter.ai/api/v1", api_key=your_key)
response = client.chat.completions.create(model="moonshotai/kimi-k2-thinking")
K2-Think is a revolutionary AI reasoning system developed by Moonshot AI that combines extraordinary performance with accessibility and affordability. Released in November 2025, this 32-billion-parameter Mixture-of-Experts model has captured developer attention by matching or surpassing much larger models like GPT-OSS 120B and DeepSeek V3.1, while maintaining inference speeds exceeding 2,000 tokens per second. With aggressive API pricing at $0.15 per million input tokens and $2.50 per million output tokens—4 to 8 times cheaper than competing models—K2-Think represents a fundamental shift in how developers can build intelligent applications. For Python developers specifically, K2-Think integration is remarkably straightforward due to full OpenAI SDK compatibility, meaning your existing code requires only minor configuration changes to leverage world-class reasoning capabilities. This guide walks you through everything from initial setup through production-ready tool orchestration patterns that harness K2-Think’s unique ability to execute 200 to 300 sequential tool calls autonomously.
K2-Think with Python delivers advanced AI reasoning to developers worldwide.
K2-Think with Python uses simple OpenAI-compatible API calls.
K2-Think with Python launched November 2025 as a 32B Mixture-of-Experts model.
K2-Think with Python matches GPT-5 performance at 4-8x lower costs.
Input costs $0.15/M tokens. Output costs $2.50/M.
K2-Think with Python Powers Autonomous Agents
K2-Think with Python builds agents handling 200-300 tool calls.
K2-Think with Python excels in research automation.
K2-Think with Python dominates document analysis.
K2-Think with Python solves complex problems.
K2-Think with Python works with your existing OpenAI SDK.
Setup K2-Think with Python in 3 Minutes
K2-Think with Python requires zero code rewrites.
pythonclient = OpenAI(base_url="https://openrouter.ai/api/v1", api_key=your_key)
response = client.chat.completions.create(model="moonshotai/kimi-k2-thinking")
K2-Think with Python delivers world-class reasoning instantly.
Why Choose K2-Think with Python?
K2-Think with Python offers transparent reasoning chains.
K2-Think with Python provides 256K token context.
K2-Think with Python costs 1/4th of GPT-5.
K2-Think with Python beats Claude on web research (60.2% vs 24%).
Understanding K2-Think Architecture and Why It Matters
K2-Think represents a fundamental breakthrough in efficient AI reasoning. Built on the Qwen2.5 base model, K2-Think achieves state-of-the-art performance through six key technical innovations: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards, agentic planning prior to reasoning, test-time scaling, speculative decoding, and inference-optimized hardware. The model’s Mixture-of-Experts architecture activates only 32 billion parameters per request from a total pool of 1 trillion, a design that fundamentally changes cost-performance calculations. This architectural efficiency means K2-Think can run effectively on consumer-grade GPU infrastructure, making sophisticated reasoning accessible to individual developers and startups without enterprise budgets.
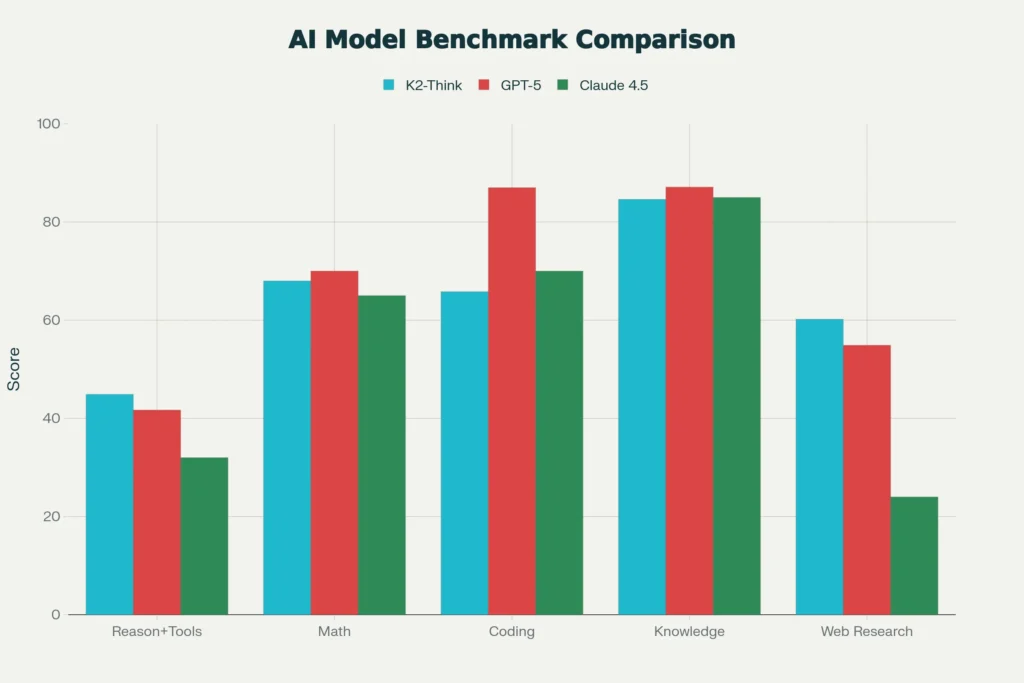
The mathematical reasoning performance alone justifies serious attention: K2-Think achieves a micro-average score of 67.99 across competitive math benchmarks, surpassing the open-source ceiling and competing directly with closed-source systems costing orders of magnitude more to operate. On the AIME 2025 benchmark, K2-Think reaches 99.1 percent accuracy, while on Humanity’s Last Exam (HLE)—a 100-subject expert-level reasoning test—K2-Think scores 44.9 percent, outperforming GPT-5’s 41.7 percent. These aren’t minor optimizations; they represent genuine advances in what smaller models can accomplish through better training approaches rather than simply scaling parameters.
Getting Started: Setting Up K2-Think in Your Python Environment
Installation requires just five steps, and you’ll be making API calls within minutes. First, create a Python virtual environment using conda or venv to isolate dependencies:
pythonconda create -n k2think python=3.10 -y
conda activate k2think
Next, install the OpenAI Python SDK, which handles K2-Think integration through OpenAI-compatible API specifications:
pythonpip install openai python-dotenv
Create a .env file in your project directory to store your API key securely:
textOPENROUTER_API_KEY=your_api_key_here
The cleanest approach uses OpenRouter as an API gateway, which provides unified access to K2-Think alongside GPT-5, Claude, and dozens of other models with a single authentication layer. OpenRouter offers $5 in free credits for new accounts, sufficient for testing multiple API calls and exploring K2-Think’s capabilities without commitment.
Initialize the OpenAI client with K2-Think configuration:
pythonimport os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY")
)
Verify the connection with a simple test query:
pythonresponse = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[{"role": "user", "content": "What is 15 * 24?"}]
)
print(response.choices[0].message.content)
This returns 360, confirming your environment is properly configured.
The Reasoning Process: Accessing K2-Think’s Transparent Thinking
One of K2-Think’s most valuable features is transparent access to its reasoning chain. Unlike models that generate answers directly, K2-Think exposes a dedicated reasoning field containing its step-by-step problem decomposition before returning final answers. This transparency proves invaluable for debugging, compliance requirements, and understanding whether the model actually reasoned through the problem or got lucky.
Access reasoning content through the message object:
pythonresponse = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[{
"role": "user",
"content": "A laptop costs $850. There's a 20% discount today, then 8% sales tax applies to the discounted price. What's the final amount I pay?"
}],
temperature=1.0
)
print("Final answer:")
print(response.choices[0].message.content)
print("\nReasoning process:")
print(response.choices[0].message.reasoning)
The reasoning field returns K2-Think’s complete thinking process: it calculates the 20% discount ($170), computes the discounted price ($680), applies the 8% sales tax ($54.40), and arrives at the final total ($734.40). This step-by-step visibility helps you verify correctness and understand failure modes when they occur—crucial for production applications where explainability matters.
Important parameter configuration: Set temperature=1.0 when using K2-Think’s reasoning capabilities. Lower temperatures constrain the model’s exploration space, which defeats the purpose of extended reasoning. Similarly, set max_tokens=4096 or higher to ensure sufficient space for reasoning chains before the final answer begins generation.
pythonresponse = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[{"role": "user", "content": "Your complex question here"}],
temperature=1.0,
max_tokens=4096
)
Tool Calling: Building Autonomous Agent Workflows
K2-Think’s most distinctive capability is extended tool orchestration—maintaining coherent goal-directed behavior across 200 to 300 consecutive tool invocations. Most models plateau after 20 to 50 tool calls as context degrades; K2-Think sustains performance across orders of magnitude more steps. This enables workflows that would be impractical with other models: autonomous research pipelines that search, cross-reference, validate findings, and iterate without human intervention; debugging sequences that test hypotheses systematically; and data processing chains that verify quality at each stage.
Defining Tool Schemas
Tool calling begins with JSON schema definitions that describe what functions the model can access and when to use them:
pythontools = [
{
"type": "function",
"function": {
"name": "analyze_csv",
"description": "Read and analyze the first N rows of a CSV file. Returns columns, sample rows, total row count, and file size.",
"parameters": {
"type": "object",
"properties": {
"filepath": {
"type": "string",
"description": "Path to the CSV file"
},
"num_rows": {
"type": "integer",
"description": "Number of sample rows to return",
"default": 10
}
},
"required": ["filepath"]
}
}
}
]
Clear descriptions in the schema are critical—K2-Think uses these descriptions to understand when each tool is appropriate and what parameters to pass. The schema format follows OpenAI’s function calling specification exactly, which extends to other OpenAI-compatible providers like OpenRouter.
Implementing Tool Functions
The schema describes what the tool does; your Python code performs the actual work:
pythonimport csv
import os
import json
def analyze_csv(filepath: str, num_rows: int = 10) -> dict:
"""Analyze a CSV file and return structure information."""
if not os.path.exists(filepath):
return {"error": f"File not found: {filepath}"}
try:
with open(filepath, 'r') as f:
reader = csv.DictReader(f)
columns = reader.fieldnames
sample_rows = [dict(row) for i, row in enumerate(reader) if i < num_rows]
f.seek(0)
total_rows = sum(1 for _ in f) - 1
return {
"columns": list(columns),
"sample_rows": sample_rows,
"total_rows": total_rows,
"file_size_kb": round(os.path.getsize(filepath) / 1024, 2)
}
except Exception as e:
return {"error": str(e)}
Building the Tool Execution Loop
Tool calling follows a request-response pattern: K2-Think identifies needed tools, you execute them, K2-Think analyzes results and continues reasoning. This loop repeats until K2-Think reaches a conclusion:
pythondef execute_tool_call(function_name: str, arguments: dict):
"""Execute a tool function based on name and arguments."""
if function_name == "analyze_csv":
return analyze_csv(**arguments)
else:
return {"error": f"Unknown function: {function_name}"}
messages = [
{"role": "user", "content": "Analyze sample_employees.csv and calculate the average salary for Engineering department employees."}
]
while True:
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=messages,
tools=tools,
temperature=1.0
)
message = response.choices[0].message
finish_reason = response.choices[0].finish_reason
messages.append({
"role": "assistant",
"content": message.content,
"tool_calls": getattr(message, 'tool_calls', [])
})
if finish_reason == "tool_calls":
for tool_call in message.tool_calls:
function_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
result = execute_tool_call(function_name, arguments)
messages.append({
"role": "tool",
"content": json.dumps(result),
"tool_call_id": tool_call.id
})
elif finish_reason == "stop":
print("Final Answer:")
print(message.content)
break
The loop maintains conversation history in the messages list, appending assistant responses with tool calls, then appending tool results with matching tool_call_id values. K2-Think uses this full history to maintain context across dozens or hundreds of interactions. Each iteration consumes tokens—be aware of context window limits—but the transparency and autonomy justify the computational cost for complex workflows.
Real-World Use Cases and Performance Patterns
K2-Think excels in specific problem domains where transparency and extended tool use provide concrete advantages. Research automation represents perhaps the clearest win: competitive analysis, market trend identification, and project scoping where K2-Think retrieves information, cross-references findings, validates claims, and synthesizes multi-source conclusions autonomously. Organizations have observed 30 percent fewer factual errors in research outputs when using K2-Think’s planning-before-reasoning approach compared to traditional generation, and 15 to 20 percent faster first drafts for writing tasks when structure is clear.
Document analysis and pattern recognition form another major category. K2-Think’s 256K token context window (expandable in some configurations) enables processing entire codebases, lengthy research papers, or multi-document analysis tasks with maintained coherence across hundreds of pages. Real testing shows K2-Think catching patterns and inconsistencies that manual analysis missed—8 out of 10 analytical tasks produced actionable recommendations when using K2-Think’s methodical hypothesis-validation approach.
On practical programming tasks, K2-Think achieves 65.8 percent on SWE-Bench Verified (measuring real GitHub issue resolution) compared to Claude 4.5’s 70 percent and GPT-5’s 87 percent, indicating that while K2-Think performs strongly on code generation, specialized models maintain an edge for pure software engineering work. However, K2-Think reaches 83.1 percent on LiveCodeBench for practical code generation scenarios, substantially ahead of Claude’s 64 percent, suggesting practical advantages in tool-assisted coding workflows.
The cost advantage compounds these benefits. At $0.15 per million input tokens and $2.50 per million output tokens, K2-Think costs approximately 1/4th as much as GPT-5 per token for identical tasks. A typical startup processing 100 million tokens monthly saves $1,032 annually compared to GPT-5, accumulating to meaningful budget savings as applications scale. For high-volume applications—content generation platforms, chatbots serving thousands of users, automated analysis tools—K2-Think’s pricing structure makes previously uneconomical workflows viable.
Practical Patterns for Production Deployments
Error handling and streaming become critical at production scale. Implement comprehensive error handling around API calls:
pythonfrom openai import RateLimitError, APIConnectionError, APIStatusError
def call_k2_with_retry(messages: list, tools: list = None, max_retries: int = 3):
"""Call K2-Think with exponential backoff retry logic."""
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=messages,
tools=tools,
temperature=1.0,
stream=False
)
except RateLimitError:
wait_time = 2 ** attempt
print(f"Rate limited. Waiting {wait_time} seconds...")
time.sleep(wait_time)
except APIConnectionError as e:
print(f"Connection error: {e}. Retrying...")
time.sleep(2 ** attempt)
except APIStatusError as e:
if e.status_code >= 500:
print(f"Server error. Retrying...")
time.sleep(2 ** attempt)
else:
raise
raise Exception(f"Failed after {max_retries} attempts")
For streaming responses, enable progressive token delivery for improved user experience:
pythonresponse = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=messages,
stream=True,
temperature=1.0
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Token tracking ensures budget predictability and prevents surprise costs. Extract usage information from responses:
pythonresponse = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=messages,
temperature=1.0
)
total_tokens = response.usage.total_tokens
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
print(f"Input: {input_tokens}, Output: {output_tokens}, Total: {total_tokens}")
# Calculate cost
input_cost = (input_tokens / 1_000_000) * 0.15
output_cost = (output_tokens / 1_000_000) * 2.50
total_cost = input_cost + output_cost
print(f"Cost: ${total_cost:.4f}")
Comparing K2-Think with Competing Models
K2-Think performs differently across problem categories, requiring task-specific evaluation. On agentic tasks requiring extensive tool use and web research, K2-Think dominates: 60.2 percent on BrowseComp (web navigation benchmark) versus GPT-5’s 54.9 percent and Claude 4.5’s 24.1 percent. The difference isn’t marginal—K2-Think’s 2.5x advantage over GPT-5 and 2.5x over Claude reflects fundamentally different training for autonomous tool orchestration.
On pure knowledge and reasoning tasks without tool access, the ranking shifts: GPT-5 leads with 87.1 percent on MMLU-Pro, with K2-Think at 84.6 percent and Claude at approximately 85 percent. This pattern holds across general knowledge benchmarks—K2-Think remains competitive but doesn’t lead, suggesting the model trades some general factual recall for enhanced reasoning and tool-use capacity.
Code generation produces the most nuanced comparison. Claude Sonnet 4.5 leads on SWE-Bench Verified (real bug-fixing) at 70 percent versus K2-Think’s 65.8 percent, but K2-Think surpasses Claude on LiveCodeBench practical code generation (83.1% vs 64%). The explanation: Claude excels at surgical code modifications, while K2-Think generates functional programs from scratch more reliably. Choose Claude for software engineering projects requiring precision code modification; choose K2-Think for building new functionality.
Cost-adjusted performance strongly favors K2-Think for most use cases. GPT-5 costs approximately 8.3 times more per input token and 4 times more per output token. A developer processing 100 million tokens monthly would spend $1,032 more on GPT-5 than K2-Think—substantial at any company size. Unless you specifically need GPT-5’s superior code modification capability or 400K token context window (versus K2-Think’s 256K), the cost savings justify adoption.
Advanced Techniques and Optimization Strategies
Plan-Before-You-Think represents K2-Think’s most powerful reasoning pattern. Rather than diving directly into problem-solving, K2-Think first generates a high-level plan, extracting key concepts and outlining relevant approach, then processes that augmented prompt through reasoning. This two-phase approach—lightweight planning followed by deep thinking—improves output quality while reducing wasted reasoning effort on dead ends.
Implement planning explicitly in your prompts:
pythonplanning_prompt = """
First, generate a high-level plan for solving this problem:
1. Extract key concepts
2. Outline the approach
3. Identify potential challenges
4. Propose solution strategy
Then solve the problem following your plan.
Problem: [Insert complex problem here]
"""
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[{"role": "user", "content": planning_prompt}],
temperature=1.0,
max_tokens=4096
)
Temperature tuning matters for reasoning consistency. K2-Think’s default of temperature=1.0 enables exploration and reasoning depth, but produces variable outputs. For deterministic results (automated decision-making, structured output), reduce temperature to 0.3-0.5, trading reasoning depth for consistency. For creative ideation or analysis requiring multiple perspectives, maintain temperature at 0.7-1.0. Test with your specific use case to find the optimal point.
Context window management becomes critical for extended interactions. K2-Think’s 256K token context accommodates very long documents, but token consumption accelerates in tool-calling loops where each interaction appends to conversation history. For production workflows, implement context pruning—summarizing older messages when context approaches limits—to maintain coherence while reducing costs.
Deployment Considerations and Best Practices
For production applications, consider three deployment approaches: the hosted API (simplest, best for startups and prototypes), self-hosted via vLLM or SGLang (highest performance control, requires GPU infrastructure), or OpenRouter integration (balanced approach with unified multi-model access). The hosted API requires no infrastructure but incurs per-token costs. Self-hosting requires significant engineering effort and hardware investment but eliminates per-token fees—economical at very high volume (billions of tokens monthly). OpenRouter offers unified access to K2-Think, GPT-5, Claude, and alternative models, enabling seamless fallback if one provider experiences issues.
Security hardening is essential for production. Never commit API keys to version control. Use environment variables, secrets managers (AWS Secrets Manager, HashiCorp Vault), or CI/CD provider secret storage. For internal APIs, implement authentication and rate limiting. For user-facing applications, validate and sanitize all user inputs before passing to K2-Think—prompt injection vulnerabilities become more severe with autonomous tool use.
Monitoring and observability prevent silent failures. Log all API calls including inputs, outputs, tokens consumed, latency, and errors. Set up alerts for sustained error rates, unusual token consumption patterns, or cost anomalies. Track reasoning content separately from final answers for analysis—examining K2-Think’s actual reasoning reveals whether quality increases or decreases as your application evolves.
Conclusion: When to Choose K2-Think
K2-Think solves a specific problem exceptionally well: complex, autonomous workflows where transparent reasoning and extended tool orchestration justify the investment in integration effort. For applications requiring simple Q&A, text generation, or straightforward classification, the complexity may not justify adoption—use Claude or GPT-5 for simpler use cases. For agentic research, multi-step analysis, detailed problem-solving with verification, or compliance-driven work requiring reasoning transparency, K2-Think’s capabilities and affordability create compelling economics.
The 4-8x cost advantage compounds over time, transforming economics for startups and resource-constrained teams. The 200-300 tool call capacity enables workflows simply impossible with other models. The transparent reasoning output supports debugging, learning, and regulatory requirements. Python integration requires minimal code changes due to OpenAI SDK compatibility.
Start with a small pilot project—implement a single tool-calling workflow or research automation task using the patterns in this guide. Monitor performance, token consumption, and output quality. Compare against your current approach. Let results from your specific use case, rather than benchmarks alone, guide final adoption decisions. The combination of world-class reasoning, affordable pricing, and elegant Python integration makes K2-Think worthy of serious consideration for any development team building AI-powered applications at scale.
Read More:Is K2-Think Open Source? Here’s What Developers Need to Know
Source: K2Think.in — India’s AI Reasoning Insight Platform.