

The global artificial intelligence landscape witnessed a groundbreaking moment in September 2025 when researchers from Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and technology powerhouse G42 unveiled K2-Think, a revolutionary reasoning system that challenges conventional wisdom about AI model development. With just 32 billion parameters, this compact yet powerful model outperforms systems 20 times its size, marking a paradigm shift from “bigger is better” to “smarter is better” in AI reasoning.
The release of K2-Think represents more than just technical achievement. It signals the United Arab Emirates’ emergence as a serious contender in the global AI race, positioning Abu Dhabi alongside Silicon Valley and Beijing as a hub for cutting-edge artificial intelligence research. But what makes this story particularly compelling is how a focused team of researchers, armed with innovative training techniques and strategic partnerships, managed to create a reasoning system that rivals the capabilities of models developed by tech giants like OpenAI and DeepSeek, while maintaining complete transparency and open-source accessibility.
The Genesis: MBZUAI’s Vision for Open AI
The story of K2-Think begins with the establishment of MBZUAI in 2019, one of the world’s first universities dedicated exclusively to artificial intelligence research and education. Founded with strong support from Sheikh Mohamed bin Zayed Al Nahyan, President of the UAE, the university was designed to be more than just an academic institution—it was envisioned as a catalyst for transforming Abu Dhabi into a global AI powerhouse.
MBZUAI’s Institute of Foundation Models (IFM), launched in early 2025, became the birthplace of K2-Think. Led by President Eric Xing, a prominent AI researcher, the institute brought together world-class talent across three global locations: Abu Dhabi, Silicon Valley, and Paris. This international collaboration allowed the team to leverage diverse expertise while maintaining strong ties to the UAE’s strategic AI vision. The institute’s mission was ambitious yet clear: produce leading foundation models across modalities while ensuring their work drives measurable, positive impact for society through open collaboration.
The decision to develop K2-Think stemmed from the institute’s commitment to demonstrating that advanced AI reasoning capabilities need not be confined to massive, resource-intensive models accessible only to well-funded corporations. The team chose to build upon Alibaba’s Qwen2.5-32B base model specifically because it had not been pre-optimized for reasoning tasks, allowing researchers to fully validate the effectiveness of their novel post-training approach.
Read More: Why K2-Think AI Model Could Replace Chain-of-Thought in Future LLMs
The Six Pillars: Engineering Excellence Over Brute Force
What sets K2-Think apart from conventional AI models is its integrated architecture built on six technical pillars that work synergistically to deliver frontier-level reasoning performance. Each pillar represents a deliberate engineering choice designed to maximize capability while minimizing computational requirements.
Long Chain-of-Thought Supervised Fine-Tuning forms the foundation. The research team utilized the AM-Thinking-v1-Distilled dataset, comprising chain-of-thought reasoning traces and instruction-response pairs spanning mathematical reasoning, code generation, scientific reasoning, instruction following, and general conversation. Unlike traditional training that focuses on final answers, this approach teaches the model to externalize its reasoning process step-by-step. The results were remarkable: within the first half epoch of training, performance on AIME 2024 jumped to approximately 79%, demonstrating rapid capability acquisition.
Reinforcement Learning with Verifiable Rewards (RLVR) represents the second pillar and a crucial innovation. Rather than relying on subjective human feedback, RLVR uses automated verification systems to assess outcomes. The team employed the Guru dataset, containing nearly 92,000 verifiable prompts across six domains: Math, Code, Science, Logic, Simulation, and Tabular reasoning. This approach creates clear training signals that guide the model toward reliable problem-solving strategies. The implementation used the GRPO algorithm via the verl library, allowing the model to directly optimize for correctness in areas where right and wrong answers are unambiguous.
Agentic Planning Prior to Reasoning, the third pillar, introduces a meta-cognitive element inspired by cognitive science research. Before tackling complex problems, K2-Think generates a high-level plan that extracts key concepts and structures the approach. This “Plan-Before-You-Think” procedure mirrors human problem-solving strategies where planning serves as a meta-thinking process guiding subsequent reasoning. Remarkably, this planning phase not only improved performance but also reduced response lengths by up to 12% compared to models without planning, addressing both quality and efficiency simultaneously.
Test-Time Scaling through Best-of-N sampling allows the model to generate multiple candidate responses (typically three) and select the most promising one through pairwise comparison by an independent language model. This approach effectively explores multiple reasoning paths without requiring massive increases in model size. Combined with planning, this technique yielded 4-6 percentage point improvements across challenging mathematical benchmarks.
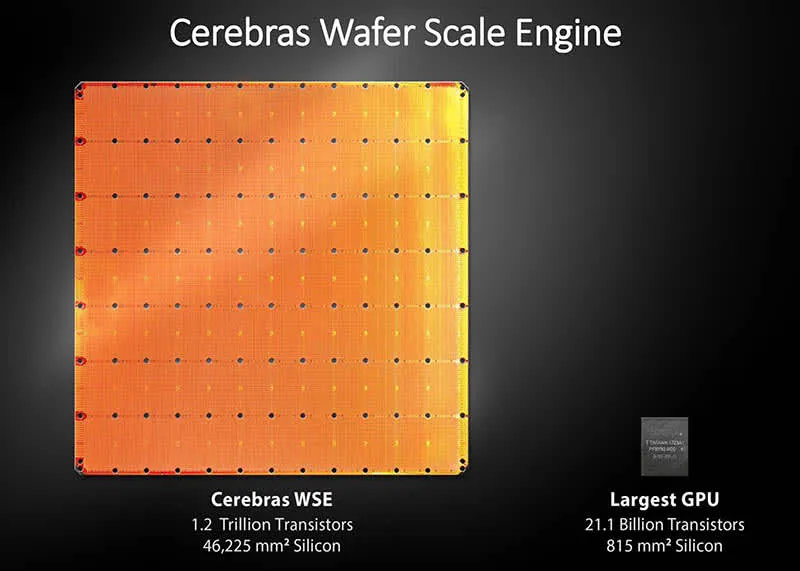
Speculative Decoding and Inference-Optimized Hardware constitute the final two pillars, focusing on deployment efficiency. The team partnered with Cerebras Systems to deploy K2-Think on the Wafer-Scale Engine (WSE), the world’s largest processor. This hardware keeps all model weights in massive on-chip memory with 25 petabytes per second of memory bandwidth—over 3,000 times more than the latest NVIDIA B200 GPU. The result: unprecedented throughput of approximately 2,000 tokens per second, enabling a 32,000-token response in just 16 seconds compared to nearly 3 minutes on typical H100 GPUs.
Breaking Benchmarks: Performance That Speaks Volumes
The true validation of K2-Think’s innovative architecture came through rigorous evaluation across competition-level benchmarks in mathematics, coding, and scientific reasoning. The results fundamentally challenged assumptions about the relationship between model size and capability.
In mathematical reasoning, K2-Think achieved a micro-average score of 67.99% across four challenging benchmarks: AIME 2024 (90.83%), AIME 2025 (81.24%), HMMT 2025 (73.75%), and Omni-MATH-HARD (60.73%). These scores are particularly significant when compared to much larger models. K2-Think surpassed DeepSeek V3.1, which operates with 671 billion parameters but achieved only 64.43% on the same benchmarks. It also exceeded GPT-OSS 120B (67.20%), a model nearly four times its size.
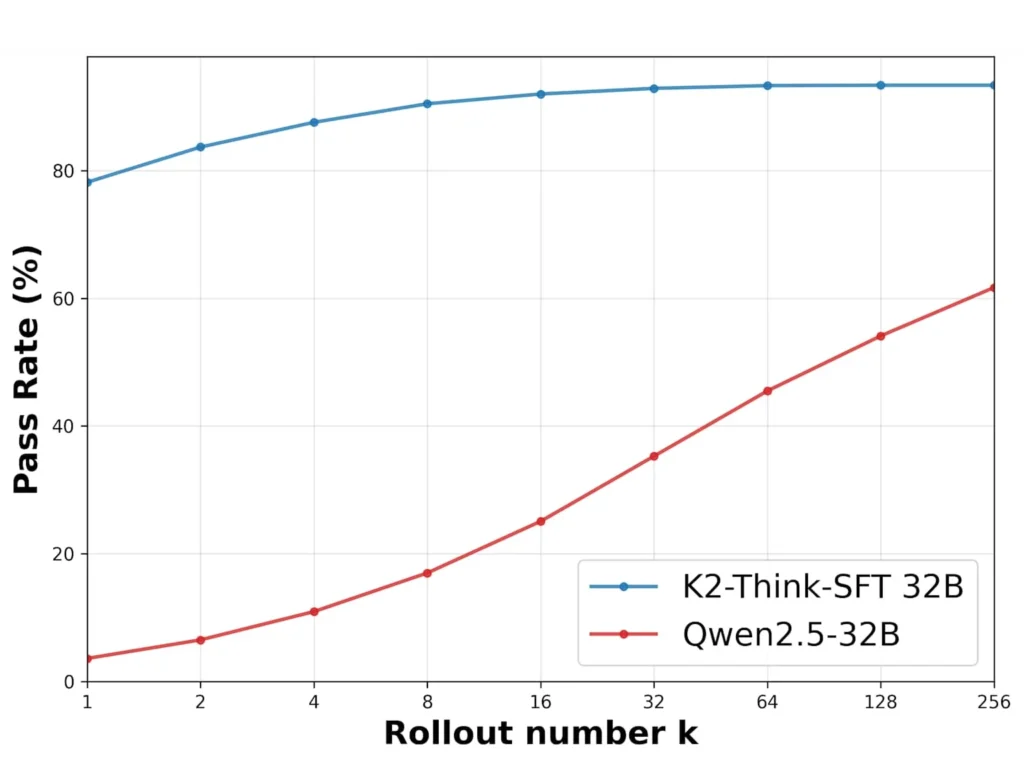
On coding benchmarks, K2-Think demonstrated versatility beyond pure mathematics. It achieved 63.97% on LiveCodeBench v5, significantly outperforming similarly sized competitors and even surpassing the larger Qwen3-235B-A22B model (56.64%). In scientific reasoning, the model scored 71.08% on GPQA-Diamond, a benchmark designed to test PhD-level questions in biology, physics, and chemistry.
Component analysis revealed that the majority of performance gains came from Best-of-3 sampling, with additional improvements from planning. When both techniques were combined with the post-trained checkpoint, the system achieved substantial improvements: AIME 2024 increased from 86.26% to 90.83%, while Omni-MATH-HARD improved from 56.74% to 60.73%. Equally important, the planning mechanism reduced token usage by 6-12% across benchmarks, making the system both more accurate and more efficient.
Open Source as Philosophy: Democratizing AI Reasoning
What truly distinguishes K2-Think from competitors is not merely its technical performance but its commitment to complete transparency and accessibility. Unlike most “open” AI models that release only weights, K2-Think provides full transparency: training data, parameter weights, deployment code, and test-time optimization code. This level of openness allows researchers worldwide to study, reproduce, and extend every aspect of the model’s development.
The decision to make K2-Think fully open-source reflects MBZUAI’s broader philosophy about AI development. Professor Eric Xing emphasized that this transparency creates “a new era of cost-effective, reproducible and accountable AI”. By documenting not just the final model but the entire post-training process for reasoning, the team aimed to allow others to replicate not only the model’s capabilities but also its reasoning development pathway.
This commitment to openness extends beyond code repositories. K2-Think is freely available through multiple channels: model weights on Hugging Face, code repositories on GitHub for both SFT training and inference, and a public web portal at k2think.ai where anyone can interact with the system. The team also offers API access for production deployments, transforming K2-Think from a static research artifact into a living, deployable system that can be stress-tested and improved by the global community.
The open-source approach positions K2-Think within Abu Dhabi’s broader strategy to lead in collaborative AI development. The UAE has consistently championed open-source AI through initiatives like the Technology Innovation Institute’s Falcon models and MBZUAI’s various foundation model projects. This strategy reflects a belief that democratizing AI access and knowledge accelerates shared progress while preventing concentration of power in the hands of a few corporations.
The UAE’s Strategic AI Ecosystem: More Than Just Research
K2-Think’s emergence cannot be understood in isolation from the UAE’s systematic investment in building a comprehensive AI ecosystem. The country’s National AI Strategy 2031 targets AI integration across nine key sectors including transport, health, space, and renewable energy. This strategic vision is supported by institutions like the Artificial Intelligence and Advanced Technology Council (AIATC) and the Advanced Technology Research Council (ATRC), which develop policies, infrastructure, and investments.
G42, K2-Think’s development partner, plays a pivotal role in this ecosystem. Founded in 2018 and chaired by Sheikh Tahnoon bin Zayed Al Nahyan, G42 has emerged as a technology holding company and global leader in AI development. With over 890 professionals and CEO Peng Xiao at the helm, G42 focuses on AI applications across government, healthcare, finance, oil and gas, aviation, and hospitality. The company has formed strategic partnerships with major corporations including Microsoft (which invested $1.5 billion in 2024), OpenAI, Oracle, NVIDIA, Cerebras, and others.
The collaboration between MBZUAI’s research excellence and G42’s infrastructure and deployment capabilities creates a powerful synergy. This public-private partnership model allows cutting-edge research to transition rapidly from academic exploration to practical deployment. The recent announcement of Stargate UAE—a 1-gigawatt computing cluster developed by G42 in partnership with OpenAI, Oracle, NVIDIA, Cisco, and SoftBank—further demonstrates the UAE’s commitment to building world-class AI infrastructure.
Competitive Context: How K2-Think Stacks Up
To appreciate K2-Think’s significance, it must be contextualized within the rapidly evolving landscape of AI reasoning models in 2025. The field has been dominated by models like OpenAI’s o3, DeepSeek’s R1, Google’s Gemini 2.5, and various open-source alternatives.
OpenAI’s o3 employs sophisticated test-time search, generating and evaluating multiple candidate chains-of-thought internally without revealing them to users. This approach enables high-performance reasoning but comes at significantly higher computational cost and with less transparency about the reasoning process. DeepSeek R1, in contrast, uses a mixture-of-experts (MoE) architecture with 671 billion total parameters and produces visible chain-of-thought reasoning. It achieves performance comparable to OpenAI’s models on math, code, and scientific tasks while being open-source and more cost-effective.
K2-Think occupies a unique position in this competitive landscape. At 32 billion parameters, it’s dramatically smaller than both o3 and DeepSeek R1, yet achieves comparable or superior performance on mathematical reasoning benchmarks. While OpenAI o3 demonstrates superior performance across the broadest range of benchmarks, K2-Think leads all open-source models in math performance specifically. Compared to DeepSeek R1, K2-Think offers similar mathematical reasoning capabilities with a fraction of the parameters, though R1 may have advantages in other domains due to its larger size and broader training.
The efficiency gains are particularly noteworthy. A study comparing reasoning models found that while o3 achieves higher accuracy, it requires significantly higher computational cost. K2-Think’s deployment on Cerebras WSE addresses this efficiency challenge directly, delivering approximately 2,000 tokens per second—making long-form reasoning practical for interactive applications.
Safety and Responsible AI: Addressing the Challenges
Recognizing that capability without safety is insufficient for responsible deployment, the K2-Think team conducted comprehensive red-teaming evaluations across four key safety dimensions. In high-risk content refusal, the model achieved a macro-average score of 0.83, with near-perfect performance on four of seven benchmarks. However, weaknesses were identified in recognizing cyber and physical risks, particularly on HarmBench (0.56) and PhysicalSafety (0.49) benchmarks.
Conversational robustness testing revealed strong resistance to sustained adversarial dialogues, with near-perfect scores on DialogueSafety and HH-RLHF benchmarks (macro-average 0.89). The model demonstrated particular strength in maintaining refusal consistency across multi-turn attempts to elicit harmful behavior.
In cybersecurity and data protection, K2-Think showed mixed results with a macro-average of 0.56. While it demonstrated robustness against leaking personal information, significant room for improvement remains in preventing assistance with cyberattacks and resisting prompt extraction attempts. Jailbreak resistance achieved a score of 0.72, with better performance on basic jailbreak attempts but vulnerabilities to more sophisticated adversarial strategies.
The overall Safety-4 macro-average of 0.75 indicates respectable but not perfect safety characteristics. The research team acknowledged these limitations transparently and emphasized ongoing work to improve the system along identified risk dimensions, particularly in cybersecurity and advanced jailbreak scenarios. This honest assessment of limitations reflects the team’s commitment to responsible AI development and deployment.
Critical Perspectives: The Controversy and Debate
Not all reception of K2-Think has been uniformly positive. Researchers at ETH Zurich’s SRI Lab published a critical analysis titled “Debunking the Claims of K2-Think,” raising concerns about evaluation methodology and reported performance. Their critique focused on three main issues: potential benchmark contamination, unfair comparisons with competing models, and the use of a “micro average” metric that heavily weights OmniMath-Hard (approximately 66% of the total score), which happens to be K2-Think’s strongest benchmark.
The contamination concerns center on the possibility that training data might overlap with evaluation benchmarks, potentially inflating performance metrics. The SRI Lab researchers also noted discrepancies when comparing K2-Think’s reported scores against those from other sources, including the Qwen3 technical report and MathArena benchmark. These criticisms highlight ongoing challenges in AI benchmarking: ensuring fair comparisons, preventing data contamination, and selecting appropriate evaluation metrics.
The MBZUAI team has not publicly responded in detail to these specific criticisms, though the comprehensive technical report accompanying K2-Think’s release does document evaluation protocols with standardized methodology across benchmarks. The debate underscores an important reality: as AI models become more sophisticated and competition intensifies, scrutiny of evaluation methods and performance claims will only increase. Transparent reporting of datasets, training procedures, and evaluation protocols—which K2-Think provides more completely than most models—becomes essential for maintaining credibility and enabling independent verification.
Real-World Applications and Future Directions
The practical implications of K2-Think extend far beyond academic benchmarks. The model’s combination of strong reasoning capabilities, efficient parameter usage, and fast inference opens new possibilities for deploying advanced AI in resource-constrained environments and interactive applications.
In education, K2-Think’s step-by-step reasoning capabilities and ability to generate detailed explanations make it suitable for tutoring systems that need to show their work. The fast inference speed on Cerebras WSE enables truly interactive problem-solving sessions where students receive near-instantaneous feedback with full reasoning traces. In scientific research, the model’s performance on GPQA-Diamond (71.08%) and strong capabilities in multi-step reasoning position it as a potential assistant for researchers tackling complex theoretical problems.
For software development, K2-Think’s 63.97% performance on LiveCodeBench and strong showing on SciCode benchmarks suggest utility in code generation and debugging tasks. The model’s ability to plan before reasoning could prove particularly valuable in decomposing complex programming challenges into manageable steps. In financial analysis, healthcare diagnostics, and other domains requiring rigorous logical reasoning with verifiable outcomes, K2-Think’s RLVR training approach provides advantages over models trained primarily on subjective feedback.
Looking forward, the K2-Think team has outlined several research directions in their technical report. First, empowering small models to “punch above their weight” through continued refinement of post-training and test-time computation techniques. The success of K2-Think at 32B parameters suggests that much of the performance gap between small and large models can be closed through strategic engineering rather than brute-force scaling.
Second, extending beyond open-source to influence the broader AI ecosystem. By demonstrating that transparency, efficiency, and capability can coexist, K2-Think provides a template for responsible AI development that balances commercial interests with public benefit. Third, exploring multi-domain generalization and expanding reasoning capabilities beyond mathematics to encompass broader knowledge-intensive tasks and real-world decision-making scenarios.
The institute has also launched initiatives to engage the broader community, including the K2-Think Hackathon in November 2025, which invited developers worldwide to build applications leveraging the model’s unique capabilities. The winning features from this competition were integrated directly into the K2-Think application, demonstrating a commitment to co-creation with users.
The Broader Narrative: What K2-Think Means for AI’s Future
K2-Think’s story resonates beyond its immediate technical achievements because it challenges several prevailing assumptions about AI development. First, it demonstrates that parameter efficiency matters. In an era where some models have grown to hundreds of billions or even trillions of parameters, K2-Think shows that 32 billion parameters, when trained and deployed strategically, can achieve frontier-level reasoning. This efficiency has significant implications for democratizing access to advanced AI, reducing environmental impact, and enabling deployment in resource-constrained settings.
Second, K2-Think validates the power of integrated approaches that combine multiple techniques synergistically. No single pillar—whether long chain-of-thought training, reinforcement learning, planning, or test-time scaling—would have produced these results in isolation. The system’s success comes from carefully orchestrating these components into a cohesive whole. This integrated engineering approach suggests that future AI advances may come as much from clever combinations of existing techniques as from fundamentally new algorithms.
Third, the model exemplifies how strategic partnerships between academia, government, and industry can accelerate AI innovation. MBZUAI’s research excellence, G42’s infrastructure and deployment capabilities, and the UAE government’s strategic vision and funding created an ecosystem where K2-Think could develop rapidly from concept to deployed system. This model of collaboration offers an alternative to the Silicon Valley approach dominated by well-funded private companies.
Fourth, K2-Think’s commitment to complete transparency sets a new standard for “open-source” AI. By releasing not just weights but training data, code, and detailed documentation of the entire development process, the team enables true reproducibility and community-driven improvement. This approach acknowledges that AI’s future should be shaped collectively rather than controlled by a small number of entities.
Finally, K2-Think symbolizes the globalization of AI leadership. For decades, cutting-edge AI research and development concentrated in the United States and, more recently, China. K2-Think’s emergence from Abu Dhabi signals that other regions—particularly those making strategic investments in talent, infrastructure, and open collaboration—can compete at the frontier of AI innovation.
Conclusion: From Abu Dhabi to the World
The story of K2-Think is ultimately about more than a single AI model. It represents a vision for how AI research and development can be conducted: with scientific rigor, engineering excellence, strategic collaboration, and a commitment to sharing knowledge for collective benefit. The journey from MBZUAI’s Institute of Foundation Models to a deployed, open-source reasoning system that rivals the capabilities of much larger proprietary models demonstrates what’s possible when talent, resources, and strategic vision align.
As AI continues to evolve at breathtaking pace, K2-Think provides important lessons. Size alone does not determine capability—strategic engineering and integration of techniques matter profoundly. Open-source development need not sacrifice performance or commercial viability. Regional hubs outside traditional centers can contribute meaningfully to the global AI ecosystem when they invest systematically in talent, infrastructure, and collaboration. And transparency in AI development, while challenging, ultimately strengthens the field by enabling scrutiny, reproducibility, and collective improvement.
The researchers behind K2-Think have not merely created an impressive technical artifact. They have demonstrated a pathway toward more efficient, accessible, and accountable AI reasoning systems. Whether this pathway becomes the dominant paradigm or one of several successful approaches remains to be seen. But the conversation about AI’s future—about the balance between scale and efficiency, opacity and transparency, concentration and democratization—has been enriched by K2-Think’s existence.
For researchers, developers, and organizations worldwide seeking to leverage advanced AI reasoning without requiring massive computational resources or accepting black-box opacity, K2-Think offers both a practical tool and an existence proof of what strategic, open AI development can achieve. For the UAE, it represents validation of a decade-long investment in positioning Abu Dhabi as a global AI hub. And for the field as a whole, it signals that the next breakthroughs in AI may come not from simply building ever-larger models, but from building smarter ones.