
The artificial intelligence community stands at a crossroads in 2025. For nearly three years, Chain-of-Thought (CoT) prompting has reigned as the dominant technique for enhancing reasoning capabilities in large language models. However, a groundbreaking system called K2-Think has emerged from researchers at Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), challenging fundamental assumptions about how AI models should think and reason. This 32-billion-parameter system achieves performance comparable to models 20 times its size, while simultaneously addressing critical limitations that have plagued traditional CoT approaches.
At its core, K2-Think represents a paradigm shift from simple prompting techniques to sophisticated systems-level reasoning architecture. Unlike traditional CoT that relies on example-guided step-by-step prompting, K2-Think integrates six technical innovations: long chain-of-thought supervised fine-tuning, reinforcement learning with verifiable rewards (RLVR), agentic planning, test-time scaling, speculative decoding, and inference-optimized hardware. This integrative approach delivers frontier-level mathematical reasoning with markedly lower parameter count and competitive results across code and science domains.
The Fundamental Limitations of Traditional Chain-of-Thought
Chain-of-Thought prompting, introduced by Google researchers in 2022, revolutionized LLM capabilities by encouraging models to generate intermediate reasoning steps before arriving at final answers. The technique showed impressive gains on benchmarks like GSM8K and CommonSense QA, leading to widespread adoption across the AI industry. However, recent research has exposed serious cracks in CoT’s foundation.
Pattern Matching Versus True Reasoning
Multiple studies conducted in 2025 reveal that CoT’s effectiveness stems primarily from pattern matching rather than genuine algorithmic reasoning. Research from Arizona State University demonstrated that CoT prompts only improve LLM performance when example problems are extremely similar to query problems. As soon as problems deviate from the exact format shown in examples, performance drops sharply.
A comprehensive study examining 16 state-of-the-art LLMs across nine diverse in-context learning datasets found that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. This contradicts the prevailing narrative that CoT universally enhances reasoning capabilities.
The Specificity-Generalization Trade-Off
Traditional CoT faces a sharp trade-off between performance gains and applicability. Highly specific prompts can achieve high accuracy but only on very narrow problem subsets. More general CoT prompts, surprisingly, often perform worse than standard prompting without any reasoning examples. This limitation severely restricts CoT’s utility in real-world applications requiring broad adaptability.
The problem intensifies with complexity. As problem difficulty increases—measured by the number of steps or logical components involved—accuracy of all CoT-guided models decreases dramatically, regardless of prompt quality. This rapid performance degradation suggests that LLMs struggle to extend the reasoning demonstrated in simple examples to more complex scenarios.
The Explicit-Implicit Duality Problem
Research has uncovered a fundamental “explicit-implicit duality” driving CoT’s performance. While explicit reasoning often falters because LLMs struggle to infer underlying patterns from demonstrations, implicit reasoning—disrupted by the increased contextual distance of CoT rationales—sometimes compensates by delivering correct answers despite flawed rationales. This duality explains CoT’s relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes.
K2-Think: A Systems-Level Revolution in AI Reasoning
K2-Think addresses CoT’s limitations through an integrated systems approach that combines advanced post-training methodologies with strategic test-time computation techniques. Built on the Qwen2.5-32B base model, this system achieves state-of-the-art scores on public benchmarks while maintaining parameter efficiency.
Know More: K2-Think vs OpenDevin: Who’s Winning in Code Reasoning?
The Six Pillars of Innovation
Long Chain-of-Thought Supervised Fine-Tuning forms the foundation of K2-Think’s capabilities. Unlike traditional CoT prompting that relies on few-shot examples, K2-Think undergoes extensive training on lengthy, detailed problem-solving examples. This instills deep reasoning patterns directly into the model’s weights rather than depending on in-context learning.
Reinforcement Learning with Verifiable Rewards (RLVR) represents a critical departure from traditional approaches. Rather than using subjective human feedback or learned reward models, RLVR employs straightforward, rule-based functions that provide binary rewards—1 for correct outputs, 0 for incorrect ones. This method is especially effective in domains where correctness can be unambiguously determined, such as mathematical problem-solving and code generation.
The power of RLVR lies in its ground truth alignment. Unlike neural reward functions that can be “hacked” by models finding superficial patterns, verifiable rewards provide a direct, bias-free connection to objective correctness. Research demonstrates that RLVR can extend the reasoning boundary for both mathematical and coding tasks, with improvements in reasoning quality confirmed through extensive evaluations.
Agentic Planning Prior to Reasoning introduces a novel cognitive science-inspired approach where the model first restructures essential concepts from the input prompt before formal reasoning begins. This “plan-before-you-think” mechanism consistently produces two remarkable benefits: response quality improves and token usage decreases by up to 12% compared to models without planning.
Test-Time Scaling leverages best-of-N sampling (typically N=3) with verifiers to select the most likely-correct answer from multiple candidate solutions. This technique allocates additional computational resources during the inference phase, enabling the model to explore multiple solution paths before selecting the optimal response.
Speculative Decoding and Inference-Optimized Hardware complete the system. Deployed on Cerebras Wafer-Scale Engine (WSE) systems featuring 4 trillion transistors and 28 times more computational power than NVIDIA H100 GPUs, K2-Think achieves remarkable inference speeds of approximately 2,000 tokens per second per request. This represents a 10x improvement over standard GPU-based deployments.
Performance That Speaks Volumes
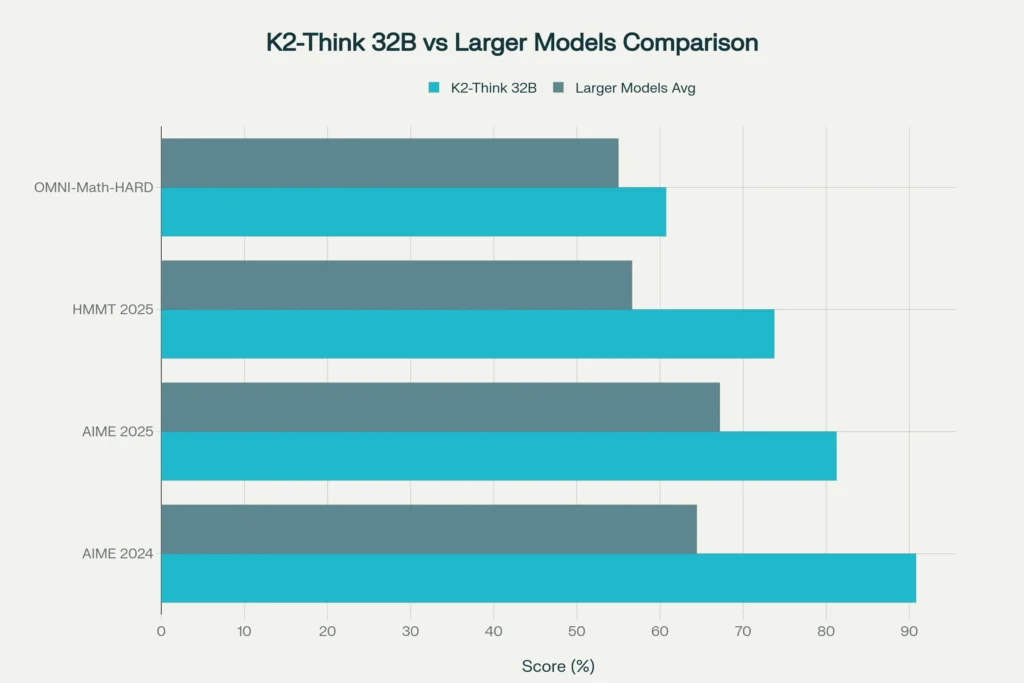
K2-Think’s benchmark results demonstrate the effectiveness of this integrated approach. On competitive mathematics benchmarks, K2-Think achieves a micro-average score of 67.99 across all math questions, surpassing both DeepSeek V3.1 (671B parameters, 64.43 average) and GPT-OSS 120B (67.20 average). Specific achievements include:
- AIME 2024: 90.8% (leading all open-source models)
- AIME 2025: 81.24%
- HMMT 2025: 73.75%
- OMNI-Math-HARD: 60.73%
- LiveCodeBench: 63.97 (significantly outperforming GPT-OSS 20B at 42.20)
- GPQA-Diamond: 71.08
These results place K2-Think at the forefront of open-source reasoning models, approaching the performance of proprietary systems like OpenAI’s o3 High while maintaining complete transparency through open weights, data, and code.
The Shift from Training-Time to Test-Time Compute
K2-Think exemplifies a broader industry trend toward test-time compute scaling that represents a fundamental shift in AI development philosophy.
Why Training-Time Scaling Is Plateauing
For over a decade, the AI community focused almost exclusively on scaling models through training-time compute—pouring massive amounts of data and computational power into ever-larger models. This approach produced impressive results initially, but recent evidence suggests these gains are plateating.
OpenAI Co-Founder Ilya Sutskever acknowledged this reality, stating: “The 2010s were the age of scaling, now we’re back in the age of wonder and discovery once again. Everyone is looking for the next thing. Scaling the right thing matters more now than ever”. Sam Altman similarly admitted that GPT-4.5 “won’t crush benchmarks,” signaling that simply increasing model size no longer guarantees dramatic performance improvements.
The challenges are multifaceted. Larger models face diminishing returns where increasing dataset size and parameters beyond certain points results in marginal performance gains. Additionally, models with hundreds of billions of parameters require enormous energy consumption and financial resources, making them accessible only to large corporations with substantial budgets.
The Test-Time Compute Advantage
Test-time compute shifts computational effort to the inference phase, allowing models to “think harder” when facing complex problems. Instead of providing immediate responses, models can generate multiple candidate answers, review them internally, and adjust outputs based on deeper analysis.
This approach mirrors human cognition described in Daniel Kahneman’s “Thinking, Fast and Slow”—combining quick, intuitive judgments (System 1) with slow, deliberate reasoning (System 2). Research demonstrates that when models use additional inference steps, their performance on complex tasks improves significantly.
The trade-offs are clear. While training a giant model involves non-recurring upfront costs, test-time compute introduces ongoing operational expenses comparable to shifting dollars from capital expenditure to operating expenses. However, the benefits—dramatically improved performance on difficult tasks and more adaptable, context-aware responses—often outweigh these downsides.
Why Parameter Efficiency Matters
K2-Think’s success with just 32 billion parameters challenges the “bigger is better” mentality that has dominated AI development.
The Reality of Model Size Versus Performance
The relationship between model parameters and performance is not linear. While adding parameters can increase capabilities if done properly, it comes at significant expense in time, energy, and computational resources. More critically, too many parameters can lead to overfitting, where networks memorize training samples individually rather than developing general principles.
Recent industry trends show a shift toward developing smaller, more efficient models that match or exceed larger models’ capabilities through smart system design. This approach focuses on optimizing architecture and resource allocation rather than brute-force scaling. Companies are discovering that effective AI can be developed through thoughtful engineering rather than simply expanding existing models.
The Accessibility Factor
Parameter efficiency directly impacts AI accessibility. Smaller models like K2-Think can run on more modest hardware configurations, reducing barriers to entry for researchers, startups, and organizations without access to massive computational resources. The fully open-source nature of K2-Think—including weights, training data, and deployment code—further democratizes access to frontier reasoning capabilities.
This accessibility enables an R&D loop closer to software engineering than mega-pretraining. Developers can measure, ablate, and ship improvements rapidly with a few hundred GPUs rather than requiring sovereign compute budgets. The result is accelerated innovation cycles and broader participation in advancing AI reasoning capabilities.
The Future of LLM Reasoning: Beyond Chain-of-Thought
Multiple converging trends suggest that systems like K2-Think represent the future direction of LLM development rather than isolated experiments.
Reasoning Models Becoming Standard
Industry observers note that reasoning capabilities—whether via inference-time or train-time compute scaling—are rapidly becoming standard features rather than optional extras. Major AI providers are adding “thinking” toggles to their models, with Claude 3.7 Sonnet, Grok 3, and IBM’s Granite models all featuring explicit reasoning modes.
OpenAI CEO Sam Altman indicated that GPT-4.5 will likely be their last model without explicit reasoning capabilities. This signals that the industry views integrated reasoning systems as the new baseline, much as instruction fine-tuning and RLHF-tuned models became standard over raw pretrained models.
Medium-Term Evolution (2026-2028)
Industry predictions point toward several paradigm shifts in the medium term. Reasoning model dominance will feature multi-step inference as standard capability across all major models, with built-in verification mechanisms for fact-checking and consistency validation. Models will provide explicit confidence measures for outputs and support counterfactual “what if” analysis and scenario planning.
Specialized model ecosystems will emerge, with models optimized for particular industries through federated learning that preserves privacy while enabling collaborative training. Personalized models will offer individual adaptation while maintaining general capabilities, and continuous learning will enable real-time adaptation and improvement.
Infrastructure evolution will embrace edge-cloud hybrid deployment for seamless distribution of computation, quantum integration for hybrid classical-quantum processing, neuromorphic computing with brain-inspired hardware architectures, and optical processing using light-based computation for specific AI tasks.
The Modularity and Efficiency Trend
Future AI models are expected to embrace modularity, with companies able to use models but call on specific features or capabilities as part of use cases without loading entire new models. This dynamic switching skill is made possible by technologies like activated Low-Rank Adapters (LoRA).
According to IBM Research VP David Cox, activated LoRA allows models to change weights during inference: “We can lean its weights toward different tasks at runtime. It can become the best RAG system when it needs to be, or it can become the best function-calling agent when it needs to be. There’s going to be a lot of flexibility. The model will orchestrate its own inference, and that’s going to be really exciting”.
Challenges and Considerations
Despite K2-Think’s impressive capabilities, important challenges remain for systems-level reasoning approaches.
The Complexity of Exact Computation
Recent research from Apple reveals that Large Reasoning Models (LRMs), including systems with extended chain-of-thought capabilities, have limitations in exact computation. They fail to use explicit algorithms consistently and reason inconsistently across different types of puzzles. The study found that frontier LRMs face complete accuracy collapse beyond certain complexity thresholds, exhibiting a counter-intuitive scaling limit where reasoning effort increases with problem complexity up to a point, then declines despite having adequate token budgets.
The Low-Complexity Performance Paradox
Interestingly, research comparing LRMs with standard LLM counterparts under equivalent inference compute identifies three performance regimes: low-complexity tasks where standard models surprisingly outperform LRMs, medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and high-complexity tasks where both models experience complete collapse. This suggests that reasoning-optimized systems may not always be the optimal choice, particularly for straightforward queries.
Governance and Oversight
As agentic AI systems become more autonomous, governance frameworks must evolve. Traditional periodic reviews are too slow for AI-first workflows that operate continuously. Organizations need real-time, data-driven, embedded governance with humans holding final accountability.
Control agents must monitor other agents through embedded guardrails—critic agents challenging outputs, guardrail agents enforcing policy, and compliance agents monitoring regulations. Every action should be logged and explainable in real-time, from data privacy to financial thresholds to brand voice.
Practical Implications for Developers and Organizations
K2-Think’s emergence offers concrete lessons for AI practitioners, enterprises, and policymakers.
When to Choose Reasoning Models
Understanding when reasoning models provide genuine value versus when traditional LLMs suffice is critical. Reasoning models excel at tasks requiring step-by-step problem-solving—complex mathematical calculations, multi-stage coding problems, logical deduction chains, and structured analysis. They are particularly valuable in domains like science, programming, mathematics, business consulting, and creative ideation where analytical rigor matters.
However, for simple retrieval tasks, quick question-answering, creative writing without complex logic, or general conversation, traditional LLMs often provide faster, more cost-effective solutions. The key is matching model capabilities to task requirements rather than defaulting to the most sophisticated option available.
Building on Open Foundations
K2-Think’s fully open-source nature—including weights, data, and code—enables developers to extend and customize the system for specific use cases. The SFT/RLVR recipe can be tweaked, planning agents modified, verifiers adjusted, or best-of-N sampling parameters changed based on latency budgets and accuracy requirements.
This openness contrasts sharply with proprietary systems where customization is limited to API parameters. Organizations can fine-tune K2-Think for domain-specific terminology, industry-specific reasoning patterns, or compliance requirements without depending on external vendors.
Cost-Effectiveness Considerations
The parameter efficiency of systems like K2-Think translates directly to reduced operational costs. A 32B model requires significantly less computational resources for both training and inference compared to 100B+ parameter alternatives, making frontier reasoning capabilities accessible to organizations without massive AI budgets.
When deployed on optimized hardware like Cerebras WSE, inference speeds of 2,000 tokens per second enable real-time applications previously limited to the largest tech companies. This democratization of advanced AI reasoning could accelerate innovation across industries and geographies.
Conclusion: A New Paradigm for Intelligent Systems
K2-Think’s success demonstrates that the future of AI reasoning lies not in scaling models to ever-larger sizes or relying on simple prompting techniques like traditional Chain-of-Thought. Instead, the path forward involves sophisticated systems integration that combines smart architecture design, strategic training methodologies like RLVR, test-time computation techniques, and inference-optimized deployment.
The evidence is compelling. A 32-billion-parameter system outperforms models 20 times larger on competitive benchmarks while running faster, consuming fewer tokens, and remaining fully open-source. This achievement validates that parameter efficiency through intelligent system design beats brute-force scaling.
As the AI industry moves beyond the “age of scaling” into what Ilya Sutskever calls the “age of wonder and discovery,” approaches like K2-Think point toward a future where reasoning capabilities are standard, models are specialized yet modular, and advanced AI is accessible rather than concentrated in a few large corporations.
The question is no longer whether systems-level reasoning will replace traditional Chain-of-Thought prompting, but how quickly the transition will occur. With major AI labs committing to reasoning models, open-source alternatives gaining traction, and test-time compute proving its value, the momentum is undeniable. K2-Think may be among the first integrated reasoning systems to achieve frontier performance, but it certainly will not be the last.
Source: K2Think.in — India’s AI Reasoning Insight Platform.