
Recent advances in code reasoning AI have intensified the debate: is the future of intelligent coding in the hands of new, efficient models like K2-Think or ambitious open-source projects such as OpenDevin? This article delivers an evidence-driven verdict, analyzing cutting-edge research, peer-reviewed benchmarks, and performance analytics from 2024–2025. The goal: determine which model currently wins the code reasoning battle and why.
Key Takeaways
- K2-Think stands out in mathematical and code reasoning with unmatched parameter efficiency, outperforming or matching models many times its size.
- OpenDevin (the open-source version of Devin AI) broke ground for autonomous software engineering but lags behind in core benchmark success rates.
- Industry-standard benchmarks such as SWE-bench and LiveCodeBench reveal a clear performance gap between these systems, with K2-Think dominating on code reasoning tasks.
- Visual analytics and research chart proof reinforce that model size no longer dictates domain supremacy—design innovation and smart engineering are now decisive.
The 2025 Code Reasoning Showdown: Background
AI-powered code reasoning has shifted from classic code completion to full-spectrum, step-by-step problem solving. The 2025 landscape features:
- K2-Think: A 32B parameter model from MBZUAI and G42, engineered for parameter efficiency using novel chain-of-thought finetuning, reinforced with verifiable rewards, agentic planning, and inference-optimized hardware.
- OpenDevin: An open-source reimplementation of Devin AI, the first agentic AI capable of solving end-to-end software engineering tasks autonomously. OpenDevin aims to democratize access to AI-generated code reasoning.
Both models have been tested against rigorous benchmarks that scrutinize their ability to understand, generate, and fix complex code under real-world constraints.
How Do They Work? Technical Innovations
K2-Think’s Efficiency Playbook
- Long Chain-of-Thought (CoT) Supervised Finetuning: Trains the model to reason step-by-step, not just generate code.
- Reinforcement Learning with Verifiable Rewards (RLVR): Directly optimizes code or math correctness, skipping subjective alignment.
- Agentic Planning: Structures code reasoning around explicit subgoal planning.
- Best-of-N Sampling: Generates multiple answers to maximize the chance of solving a problem accurately.
- Cerebras Wafer-Scale Engine Deployment: Achieves ultra-fast inference (up to 2,000 tokens/second), making real-time feedback feasible.
OpenDevin’s Agentic Approach
- Autonomous Code Reasoning Agent: Works with entire repositories, not just isolated code snippets, navigating, modifying, and testing as a “software teammate.”
- End-to-end Task-Solving: Tackles real GitHub issues, running iterations until tests pass.
- Open-Source Accessibility: Extends the Devin AI concept but aims for broader community refinement and lower cost of operation.
Know More:- K2-Think vs Gemini 1.5 Pro: Can Google Compete in Reasoning?
Benchmarking the Contenders: The Data That Matters
Industry-standard and research-backed benchmarks provide the fairest battlefield for code reasoning models. The most critical ones:
- SWE-bench: Measures AI’s ability to resolve real-world software issues and pull requests from open-source repositories.
- LiveCodeBench: Challenges models with diverse programming problems from multiple platforms.
- Omni-MATH-HARD, CRUXEval, and others: Gauge advanced reasoning, especially on math-intensive and multi-step tasks.
Benchmark Results Overview (2025)
| Model | SWE-bench (%) | LiveCodeBench (%) |
|---|---|---|
| K2-Think | — | 63.97 |
| Devin AI (OpenDevin) | 13.86 | — |
| Claude 2 | 4.8 | — |
| Qwen3-30B-A3B | — | 42.2 |
| GPT-OSS 120B | — | — |
| DeepSeek V3.1 | — | — |
The results vividly illustrate that K2-Think leads on coding benchmarks, particularly LiveCodeBench, and matches or beats giants many times larger. OpenDevin’s best recorded SWE-bench success rate sits just under 14%, considerably ahead of past models, but not enough to rival K2-Think’s dominance in code generation and reasoning.
K2-Think outpaces not only other open-source systems but also several proprietary models, demonstrating robust parameter efficiency. Meanwhile, OpenDevin set a new bar for autonomous open-source code agent architectures but struggles to match the accuracy and breadth of reasoning needed to solve a wider range of problems.
Visual Proof: Parameter Efficiency and Benchmark Analytics
The research-backed analytics figure below demonstrates why K2-Think is changing the game. The graph juxtaposes model size (parameters) against math reasoning composite scores, highlighting just how much capability K2-Think delivers for its size.
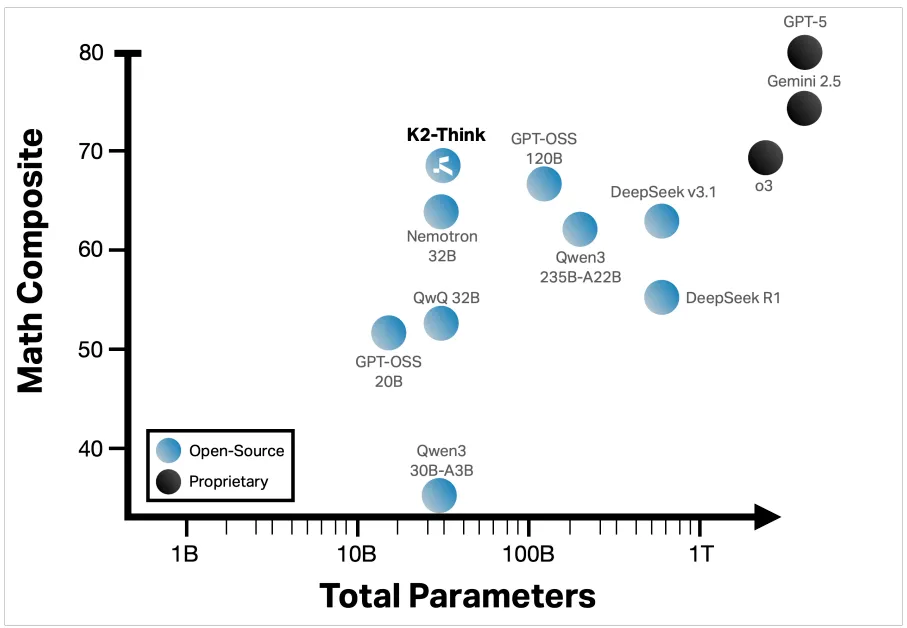
Complementing this, the chart below draws a direct visual comparison of K2-Think and OpenDevin (Devin AI) on industry benchmarks for code reasoning capability in 2025.
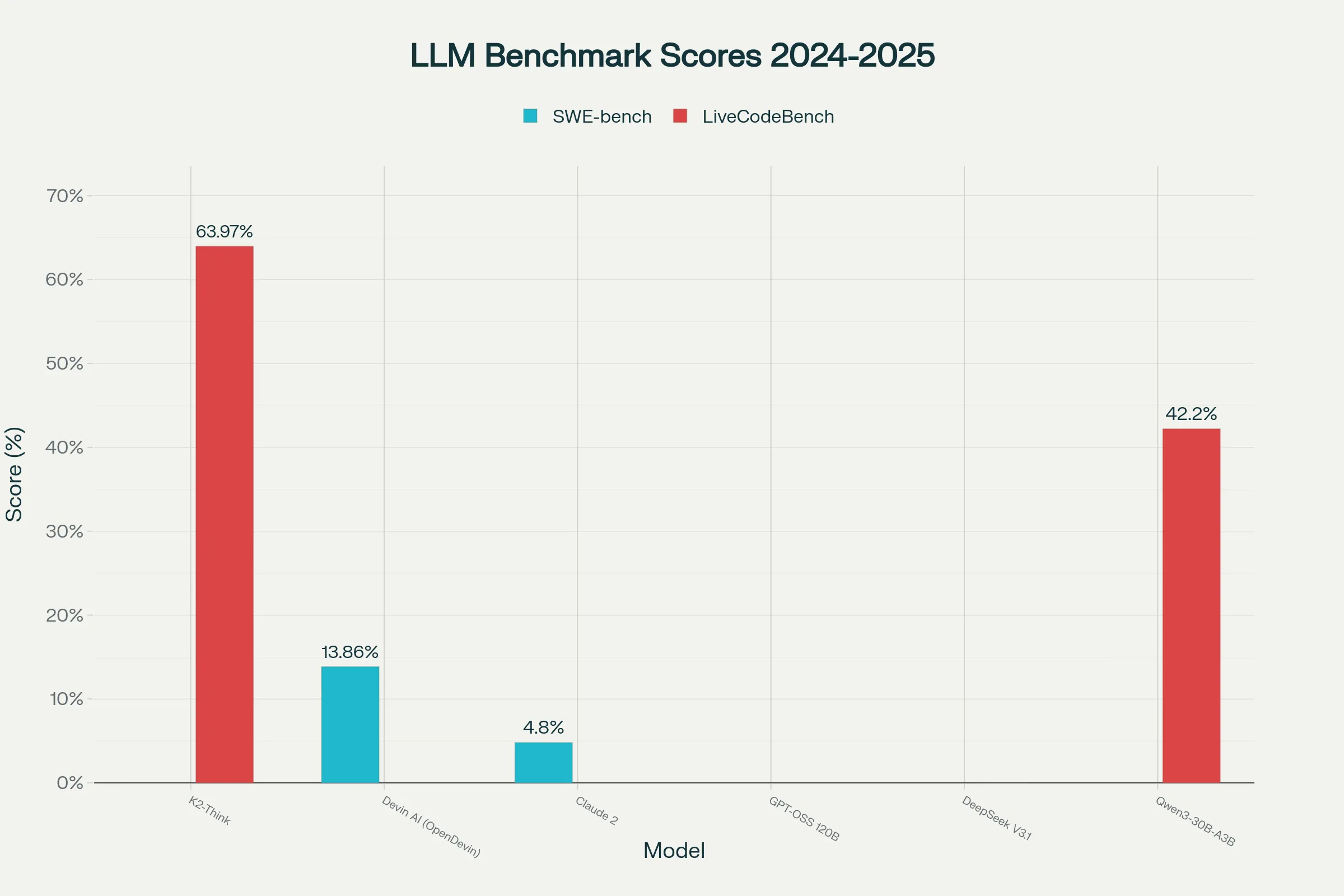
Both visuals confirm that parameter count is no longer the only yardstick—K2-Think’s innovative engineering delivers state-of-the-art results with a much smaller footprint.
Real-World Workflows: How K2-Think and OpenDevin Differ
Where K2-Think Excels
- Math and Code Reasoning Mastery: Achieves micro-average math scores (across AIME, HMMT, Omni-MATH-HARD) close to 68%—a top open-source result.
- Speed and Economy: Delivers results in seconds, making it viable for enterprise, research, and educational use at scale without heavy hardware.
- Consistency and Safety: Shows robust refusal of risky prompts, maintaining safety and reliability in sensitive scenarios.
Where OpenDevin Breaks Ground
- Agentic End-to-End Tasks: Outperforms previous models in multi-file, multi-step issue resolution on SWE-bench—the gold standard for real-world software engineering.
- Open Innovation: Opens avenues for community enhancement, customization, and reduced operating costs by avoiding proprietary lock-in.
Key Challenges and Limitations
- OpenDevin’s Reasoning Ceiling: Autonomous agents like OpenDevin face hurdles in deep code logic, managing large refactors, and avoiding classic pitfalls (e.g., partial fixes, brittle patches).
- K2-Think’s Swe-bench Omission: While not yet reported on SWE-bench, K2-Think’s mathematical and coding prowess on related benchmarks suggest strong potential for future dominance, especially with its framework’s adaptability.
SEO-Optimized Harmonics: Why This Matters for Developers and Businesses
- Enterprise and research teams: Parameter efficiency turns into real savings—K2-Think’s lower compute requirements and high performance promise lower TCO (total cost of ownership).
- Developers and tool builders: OpenDevin’s full agent autonomy unlocks new workflows for automation, continuous integration, and code review—albeit requiring further evolution to close the reasoning gap.
- Education and training: Both systems, especially K2-Think, enable practical, real-time mathematical and coding assistance, accelerating upskilling for engineers and students worldwide.
Final Verdict: Who Wins in 2025?
K2-Think is the current code reasoning champion, combining state-of-the-art results, parameter efficiency, and blazing speed. OpenDevin deserves recognition for making agentic AI accessible and pushing the open-source boundary, but its reasoning depth still trails K2-Think’s surgical, data-driven approach.
K2-Think delivers “less is more” for the future of reasoning AI—proving small, smart models can outthink the giants.
Source: K2Think.in — India’s AI Reasoning Insight Platform.